高性能计算服务
>
软件专区
>
最佳实践
>
基于Atomate2工作流计算材料弹性矩阵并自动后处理输出弹性模量
Atomate2 是由 Materials Project 团队开发的开源材料科学工作流管理系统,旨在通过简单的 Python 函数实现复杂的第一性原理计算自动化。它基于 pymatgen、custodian、jobflow 和 FireWorks 等开源库构建,支持高通量计算和材料属性预测,广泛应用在电池材料、半导体、催化等领域。
本次实操,我们将介绍如何在超算互联网使用Atomate2工作流计算材料弹性矩阵并自动后处理输出弹性模量。以Si单质为例,展示从到结构文件读取到工作流执行、自动化数据后处理的完整流程,并提供完整的 Python 脚本代码,为进一步研究不同材料的弹性特性构建了标准化、可复现的工作流框架。
采用conda进行环境管理以免与其他python环境依赖冲突
conda create -n atomate2 python切换到atomate2环境后直接pip一键安装即可
conda activate atomate2
pip install atomate2实际计算的输入文件自动生成和数据后处理需要使用pymatgen,安装Atomate会一起安装pymatgen,因此只需要配置势函数即可:https://pymatgen.org/installation.html
在超算用户家目录下新建一个atomate2文件夹,并新建config、log两个字文件夹:
atomate2
├── config
└── logs
在config文件夹中新建jobflow.yaml文件
jobflow.yaml文件定义工作流的信息以及任务的输入和输出路径数据库。官网介绍了怎么通过云端数据库进行连接。受限于网络等限制,该方法国内用户可能会有连接问题。
因此,这里主要介绍如何通过本地json文件进行配置,只需要安装jobflow.yaml文件:
JOB_STORE:
docs_store:
type: JSONStore
paths: CURRENT_DIR.json
read_only: False
additional_stores:
data:
type: JSONStore
paths: CURRENT_DIR.json
read_only: False计算路径可以在jobflow.yaml中指定,也可以在每次计算的python脚本中指定。
在config文件夹中新建atomate2.yaml文件
atomate2.yaml文件用于记录软件运行中各种的命令,这里需要定义一下VASP的运行命令:
下面是一个超算互联网上vasp任务的提交脚本:
#!/bin/bash
#SBATCH -J vasp
#SBATCH -N 1
#SBATCH --ntasks-per-node=32
#SBATCH -p wzhctest
module purge
source /work/home/andyhox/apprepo/vasp/6.4.2-ioptcell_intelmpi2017_hdf5_libxc/scripts/env.sh
export MKL_DEBUG_CPU_TYPE=5 #加速代码
export MKL_CBWR=AVX2 #使cpu默认支持avx2
export I_MPI_PIN_DOMAIN=numa #内存位置与cpu位置绑定,加速内存读取。对于内存带宽要求高的计算提速明显
srun --mpi=pmi2 vasp_std在atomate2.yaml文件中只需要加入下面的命令即可:
VASP_CMD: srun --mpi=pmi2 vasp_std在环境变量中加入atomate2配置文件
在.bashrc中加入:
export ATOMATE2_CONFIG_FILE="/work/home/andyhox/atomate2/config/atomate2.yaml"
export JOBFLOW_CONFIG_FILE="/work/home/andyhox/atomate2/config/jobflow.yaml"文件的路径换成你的atomate2文件夹路径即可。
第二步,我们以Si单质弹性模型计算为例,展示从到结构文件读取到工作流执行的完整流程。
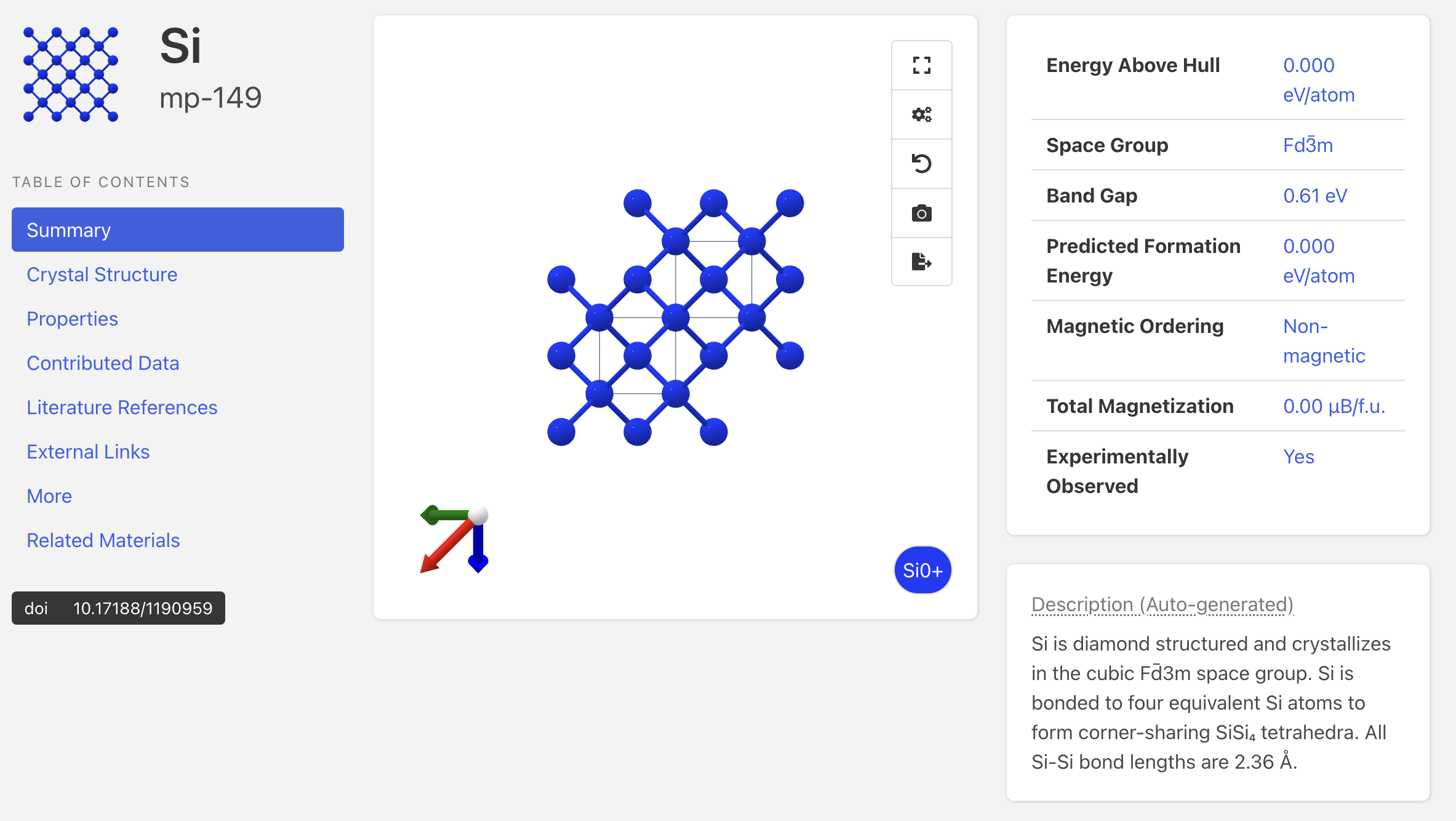
Si单质原胞的结构如下:
# 导入包
from jobflow import run_locally, SETTINGS
import os
# 工作路径
work_dir = os.getcwd()
# 定义数据数据库
docs_path = os.path.join(work_dir,'docs')
data_path = os.path.join(work_dir,'data')
os.makedirs(docs_path,exist_ok=True)
os.makedirs(data_path,exist_ok=True)
SETTINGS.JOB_STORE.docs_store.paths = [os.path.join(docs_path,'doc.json')]
SETTINGS.JOB_STORE.additional_stores['data'].paths = [os.path.join(data_path,'data.json')]代码解释:
# 定义数据数据库
docs_path = os.path.join(work_dir,'docs')
data_path = os.path.join(work_dir,'data')
os.makedirs(docs_path,exist_ok=True)
os.makedirs(data_path,exist_ok=True)上述代码在当前文件夹下新建docs、data两个文件夹用来储存数据。
SETTINGS.JOB_STORE.docs_store.paths = [os.path.join(docs_path,'doc.json')]
SETTINGS.JOB_STORE.additional_stores['data'].paths = [os.path.join(data_path,'data.json')]上述代码将jobflow.yaml文件中的路径重定向为当前路径下的docs和data两个文件夹路径。
其中docs文件夹储存doc.json文件,该文件用于储存数据量较小的数据,例如结构,计算参数,计算过程的离子比和电子步;
data文件夹储存data.json文件,该文件用于储存数据量大的数据,例如能带、态密度的计算结果。
# 导入包
from pymatgen.core.structure import Structure
from atomate2.vasp.flows.elastic import ElasticMaker
import os
# 读取结构
struct = Structure.from_file(os.path.join(work_dir,'Si.cif'))
# 直接调用工作流
elastic_flow = ElasticMaker().make(struct)
# 运行工作流
run_locally(elastic_flow, create_folders=True)代码解释:
from atomate2.vasp.flows.elastic import ElasticMakerElasticMaker是Atomate2内置的工作流,可以直接使用。弹性常数的计算方法为能量--应变方法。
from atomate2.vasp.flows.elastic import ElasticMaker
from jobflow import run_locally, SETTINGS
from pymatgen.core.structure import Structure
import os
work_dir = os.getcwd()
# 定义数据数据库
docs_path = os.path.join(work_dir,'docs')
data_path = os.path.join(work_dir,'data')
os.makedirs(docs_path,exist_ok=True)
os.makedirs(data_path,exist_ok=True)
SETTINGS.JOB_STORE.docs_store.paths = [os.path.join(docs_path,'doc.json')]
SETTINGS.JOB_STORE.additional_stores['data'].paths = [os.path.join(data_path,'data.json')]
# 读取结构
struct = Structure.from_file(os.path.join(work_dir,'Si.cif'))
# 直接调用工作流
elastic_flow = ElasticMaker().make(struct)
# 运行工作流
run_locally(elastic_flow, create_folders=True)如果是在本地进行计算,可直接运行上述代码。如果需要提交到超算集群上进行计算,则需要修改一下提交脚本:
#!/bin/bash
#SBATCH -J vasp
#SBATCH -N 1
#SBATCH --ntasks-per-node=16
#SBATCH -p wzhctest
module purge
source /work/home/andyhox/apprepo/vasp/6.4.2-ioptcell_intelmpi2017_hdf5_libxc/scripts/env.sh
export MKL_DEBUG_CPU_TYPE=5 #加速代码
export MKL_CBWR=AVX2 #使cpu默认支持avx2
export I_MPI_PIN_DOMAIN=numa #内存位置与cpu位置绑定,加速内存读取。对于内存带宽要求高的计算提速明显
source activate atomate2
python elastic_workflow.py &> log需要修改的只有最后两行,即进入atomate2的环境,然后运行对应的python脚本即可。
提交脚本中不需要填写vasp的运行命令,因为在之前的atomate2.yaml文件中已经指定。
此时工作目下只需要有三个文件即可:

然后正常提交任务即可:sbatch vasp.slurm
计算完成后,工作目录下会生成一系列job_开头的文件夹,每一个文件夹都表示工作流中的一个子任务。

我们需要处理的数据全部在docs文件夹里面的doc.json文件里面:
可以看到doc.json文件的内容不是非常好读,当然了,我们分析数据也不是直接去查找文件,同样也是通过代码去查询。
查询代码
写一个query.py脚本查询数据
# 导入包
from jobflow import SETTINGS
from pprint import pprint
import pandas as pd
import os
# 工作目录
work_dir = os.getcwd()
# 数据库路径
docs_path = os.path.join(work_dir,'docs')
data_path = os.path.join(work_dir,'data')
SETTINGS.JOB_STORE.docs_store.paths = [os.path.join(docs_path,'doc.json')]
SETTINGS.JOB_STORE.additional_stores['data'].paths = [os.path.join(data_path,'data.json')]
# 连接到数据库
store = SETTINGS.JOB_STORE
store.connect()
# 查询弹性矩阵
elastic_tensor = store.query_one(
{'name':'fit_elastic_tensor'},
properties=['output.elastic_tensor']
)
data = pd.DataFrame(elastic_tensor['output']['elastic_tensor']['raw'], index=None)
print(data)
# 查询弹性性质
derived_properties = store.query_one(
{'name':'fit_elastic_tensor'},
properties=['output.derived_properties']
)
elastic_properties = derived_properties['output']['derived_properties']
df = pd.DataFrame(list(elastic_properties.items()), columns=["Property", "Value"])
print(df)此时结果可输出6X6的弹性矩阵:

以及处理好的体模量、弹性模量、德拜温度、泊松比等性质:
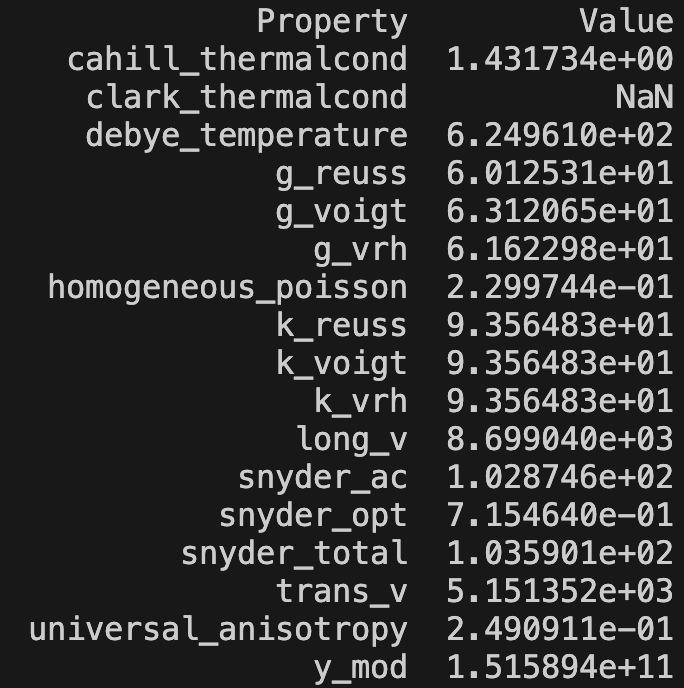
每个property对应的意思如下:
k_voigt:Voigt average of the bulk modulus.
k_reuss: Reuss average of the bulk modulus.
k_vrh: Voigt-Reuss-Hill average of the bulk modulus.
g_voigt: Voigt average of the shear modulus.
g_reuss: Reuss average of the shear modulus.
g_vrh: Voigt-Reuss-Hill average of the shear modulus.
universal_anisotropy: Universal elastic anisotropy.
homogeneous_poisson: Homogeneous poisson ratio.
y_mod: Young’s modulus (SI units) from the Voight-Reuss-Hill averages of the bulk and shear moduli.
trans_v: Transverse sound velocity (SI units) obtained from the Voigt-Reuss-Hill average bulk modulus.
long_v: Longitudinal sound velocity (SI units) obtained from the Voigt-Reuss-Hill average bulk modulus.
snyder_ac: Synder’s acoustic sound velocity (SI units).
snyder_opt: Synder’s optical sound velocity (SI units).
snyder_total: Synder’s total sound velocity (SI units).
clark_thermalcond: Clarke’s thermal conductivity (SI units).
cahill_thermalcond: Cahill’s thermal conductivity (SI units).
debye_temperature: Debye temperature from longitudinal and transverse sound velocities (SI units).
通过上述步骤,可以形成两个固定的计算弹性常数的脚本:
针对不同的结构,只需要在elastic_workflow.py中替换一下读取的结构即可,其余的操作不变。
以上,我们就完成了如何在超算互联网使用Atomate2工作流计算材料弹性矩阵并自动后处理输出弹性模量的实践详解。
希望本篇最佳实践为您提供一些有价值的信息和实践技巧。