核心节点用户手册
>
平台应用软件使用
>
AI类应用
AI内容当前适配情况(部分):
| 所属板块 | 产品 | 内容分类 | 推荐内容 | 使用场景 |
|---|---|---|---|---|
| 控制台 | Notebook-基础镜像模型训练-基础镜像 | 基础/训练框架 | PyTorch 2.4/2.5,TensorFlow 2.13/2.18,Jax0.4.34,Paddle3.0.0 | 包含了深度学习最核心的数学库和算子,用于模型开发、训练、微调 |
| 推理引擎 | vLLM0.9.2,MIGraphX5.1.0,Sginfer0.0.2 | 用于把模型部署为推理服务,具备优于使用基础框架部署的延迟,吞吐 | ||
| 模型部署-模型镜像 | 文本生成 | Qwen3-webui/api,Deepseek R1 api,SeedCoder_vllm等 | 用于对话、逻辑推理、代码生成类模型服务的一键部署 | |
| 文档处理OCR | HunyuanOCR,MinerU_vllm,DeepSeekOCR等 | 专注于从图片、PDF 或扫描件中提取结构化信息 | ||
| 多模态生成 | qwen-image-edit,hunyuanvideo-foley,Fish-Speech2,ChatTTS2等 | 修图、短视频创作,配音、语音转文字,看图说话、图表分析、复杂视觉推理 | ||
| 向量化 | qwen3-embedding-api,qwen3-reranker-api | 用于知识库检索(RAG)中的向量化和重排序任务 | ||
| AI社区 | 模型 | 文本生成/向量化 | DeepSeek系列,Qwen3系列,ERNIE-4.5系列,GLM系列等 | 模型查找、下载、开发社区的模型不同于控制台的模型镜像,精品模型连接了在线WebUI体验,免费试用,比镜像使用门槛更低 |
| 文档处理OCR | MonkeyOCR,UniPic2-Metaquery,MinerU,DeepSeek OCR等 | |||
| 图片/视频/语音/3D | LTX-Video,Qwen-Image,CosyVoice,CogVideoX等 | |||
| 多模态 | Qwen2.5-VL,Janus-Pro,Ovis2.5,MiniCPM-V-4等 | |||
| 智能体 | 对话聊天 | MiniCPM-V,Hunyuan-MT-7B | 理解人类意图、进行文字对话、多语言翻译以及对图像内容进行理解和描述 | |
| 图片/视频/语音生成 | 图像编辑:Z-Image-Turbo,Hunyuan-DiT,Qwen-Image-Edit,Step1X-Edit等 视频与数字人:Wan-2.2-5B,Wan2.1-ComfyUI,Wan2.2-Animate-14B 语音、音乐与音效:ChatTTS,ACE-Step,HunyuanVideo-Foley,SoulX-Podcast | 最热门的AIGC内容创作工具,涵盖了从静态图片到动态视频、从声音合成到音乐音效的全方位生成能力 | ||
| MCP/RAG/Agent | MinerU (2.5/2.7),Deepseek-OCR,HunyuanOCR,Dot-OCR,ASR等 | 构建Agent/RAG的工具,侧重于将非结构化数据转化为机器可理解的信息 |
AI模型适配情况:
| 模型 | 模型名称 | 训练/微调 | 精度 |
|---|---|---|---|
| 大语言模型 | Qwen3系列 3b、14b、32B | 微调 | BF16/FP16 |
| DeepSeek系列 7B、14B、32B、70B | 微调 | BF16/FP16 | |
| Llama系列 8B、70B | 全量训练/微调 | BF16/FP16 | |
| 视觉模型 | 包含yolo系列、bev系列、unet等 | 训练/微调 | Fp32/fp16 |
| ocr | 测试包含了mineru、DBNet、PaddleClas等模型 | 推理 | Fp32 |
| 多模态 | 当前主要测试了语音、文本场景 | 微调 | BF16/FP16 |
| 语音 | Wenet、F5-TTS | 微调 | fp32 |
MaaS服务提供Chatbot、API服务,支持的模型包括千问系列、DeepSeek满血版、和Minimax系列。
具体使用可参考控制台>人工智能>模型API>接口文档。 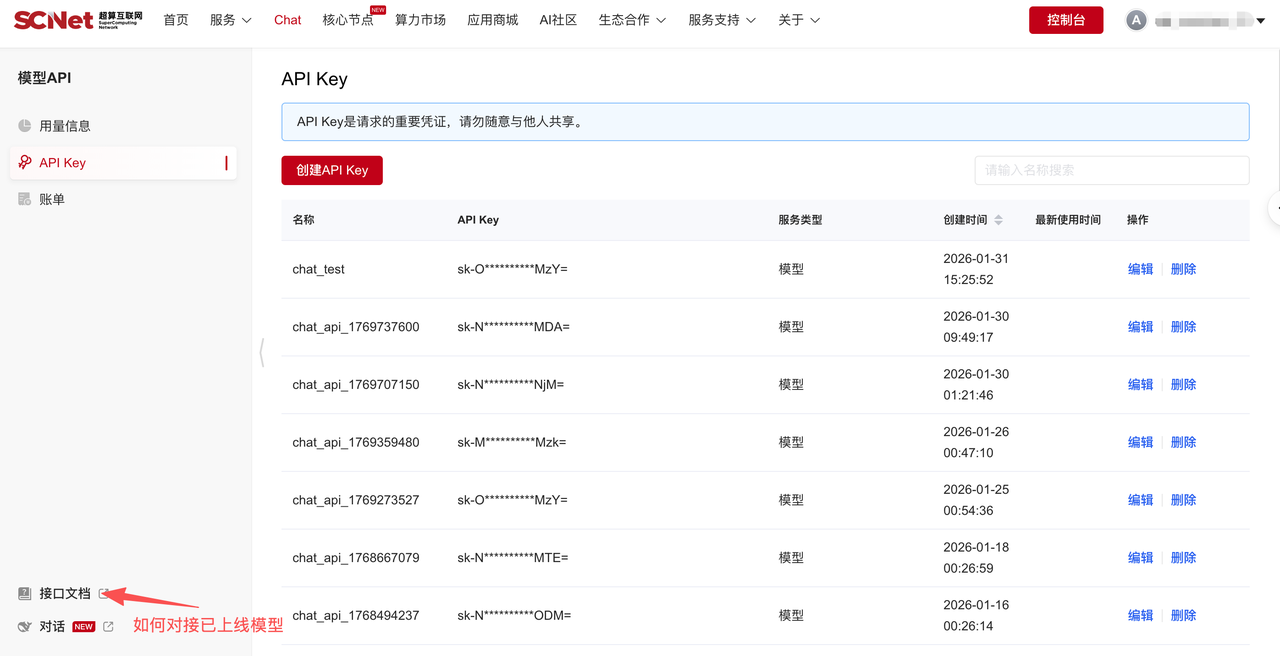
点击首页>服务>人工智能。 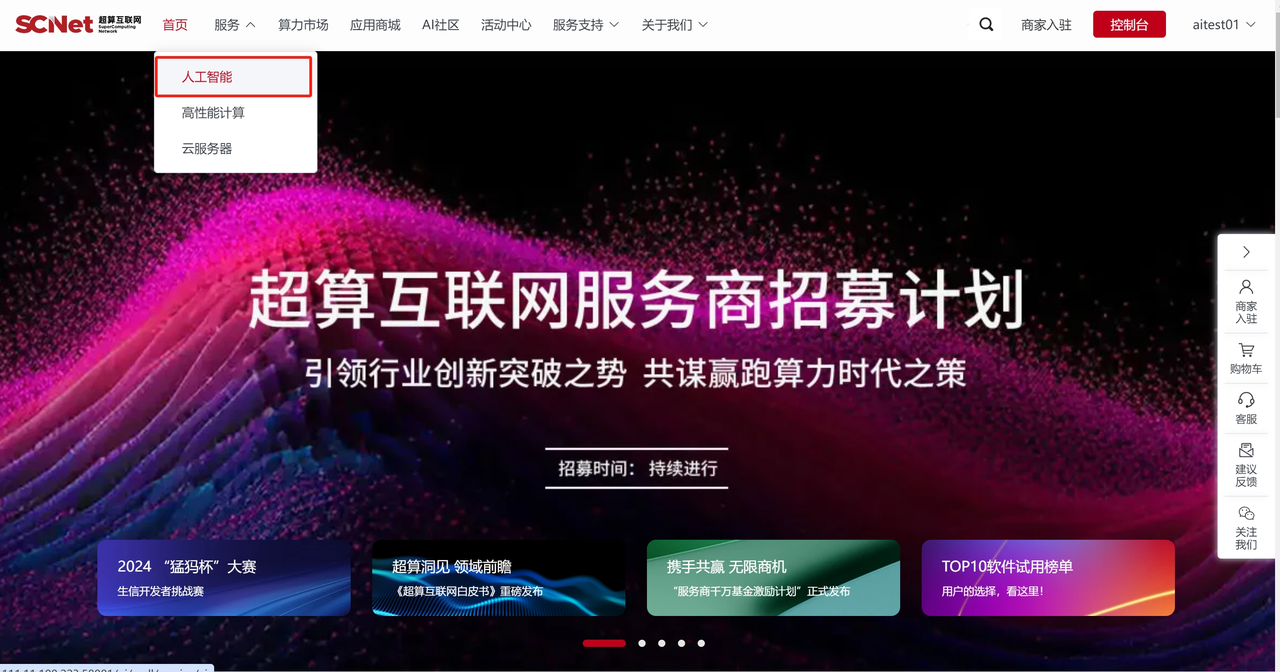 点击“去使用“进入创建Notebook界面。
点击“去使用“进入创建Notebook界面。 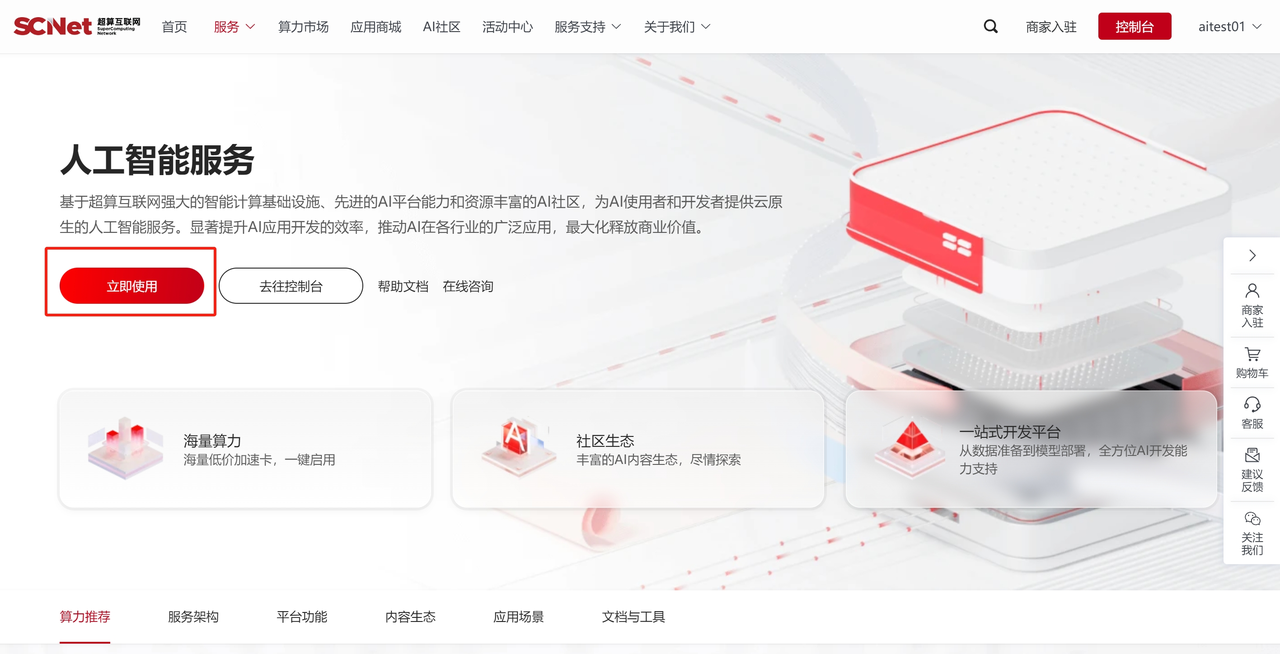 界面展示创建Notebook容器实例列表,选择创建Notebook即可创建新的Notebook容器实例。
界面展示创建Notebook容器实例列表,选择创建Notebook即可创建新的Notebook容器实例。 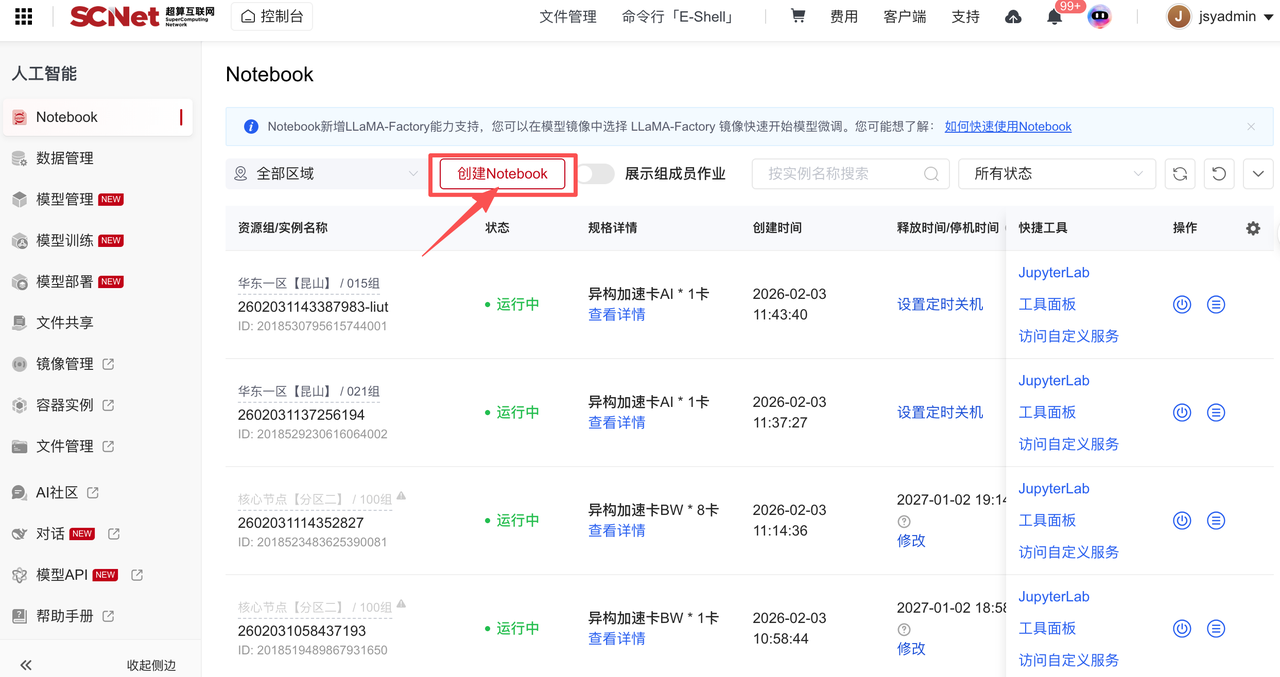 在创建Notebook界面选择区域、加速卡型号、加速卡数量、开发镜像等。其中:
在创建Notebook界面选择区域、加速卡型号、加速卡数量、开发镜像等。其中:
(1)在选择加速卡时可用卡数展示的是您当前可用的最大加速卡数量,根据需求选择卡的类型和卡数;
(2)基础镜像涵盖Pytorch、TensorFlow等主流框架、额外提供模型镜像方便立即试用。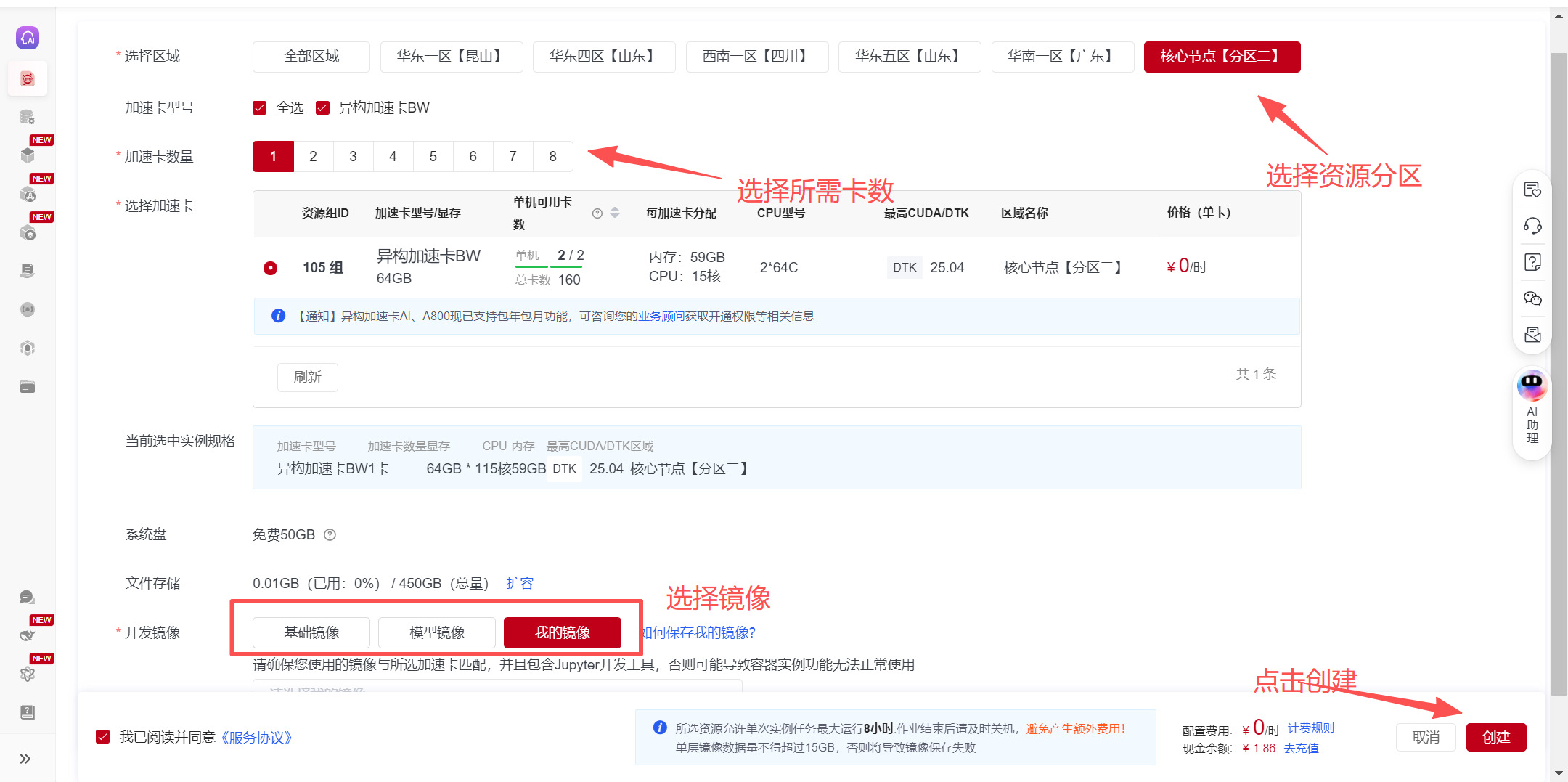
进入控制台,在控制台首页,选择“人工智能”进入创建Notebook界面。 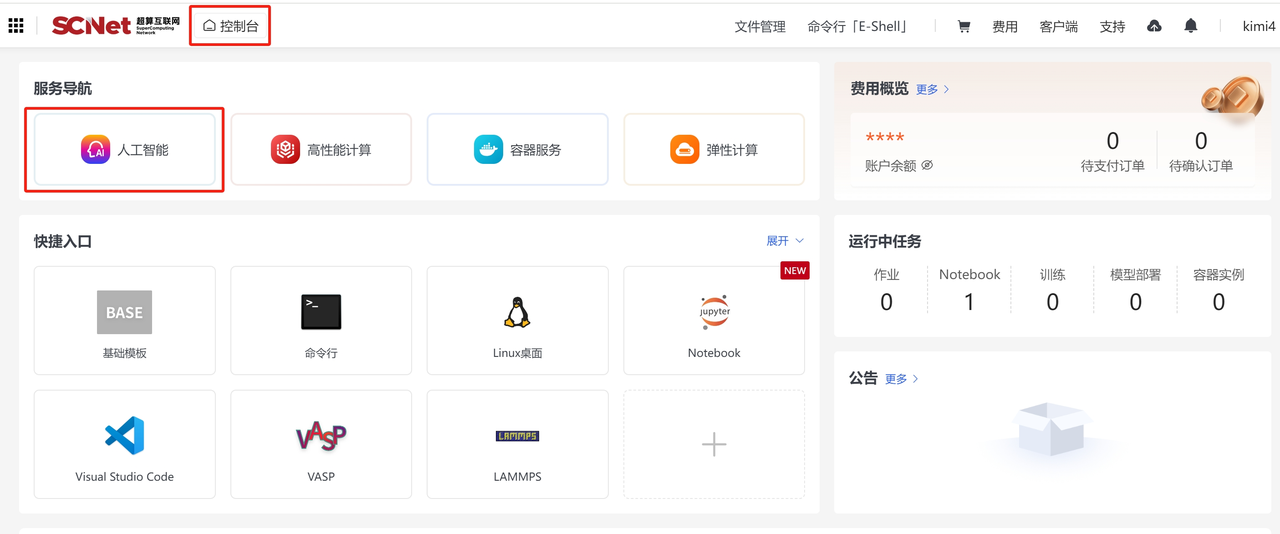 界面展示创建Notebook容器实例列表,选择创建Notebook即可创建新的Notebook容器实例
界面展示创建Notebook容器实例列表,选择创建Notebook即可创建新的Notebook容器实例
Bash
# 构建一个虚拟环境名为:my-env,Python版本为3.7
conda create -n my-env python=3.7
# 更新bashrc中的环境变量
conda init bash && source /root/.bashrc
# 切换到创建的虚拟环境:my-env
conda activate my-env
# 验证
python| 序号 | 镜像 | 描述 |
|---|---|---|
| 1 | jupyterlab-langchain-chatllm:pytorch2.1.0-cuda12.1-py3.10-model | 基于Langchain与ChatGLM3-6B语言模型的本地问答 |
| 2 | jupyterlab-yolov5:pytorch2.2.0-py3.10-cuda12.1-model | 基于 YOLOv5 算法的多目标检测工具,用于提供高效、精确的目标识别功能 |
| 3 | jupyterlab-stable-diffusion-webui:pytorch2.2.0-py3.10-cuda12.1-model | 带 WebUI 的文生图工具,用于将文本输入生成高质量图像 |
| 4 | jupyterlab-bert-vits2:pytorch2.1.0-py3.10-cuda12.1-model | 基于Bert-Vits2的高级语音合成模型,用于生成高质量的自然语音 |
您可以在“控制台>容器服务>镜像管理”中进行查看和管理镜像,便于在不同任务中直接选择使用。
a. 保存镜像。在实例运行中或关机后,在更多操作中点击保存镜像,则可以将该实例的整个环境保存至我的镜像。 
b. 查看镜像。在“控制台>容器服务>镜像管理>我的镜像”中查看镜像。 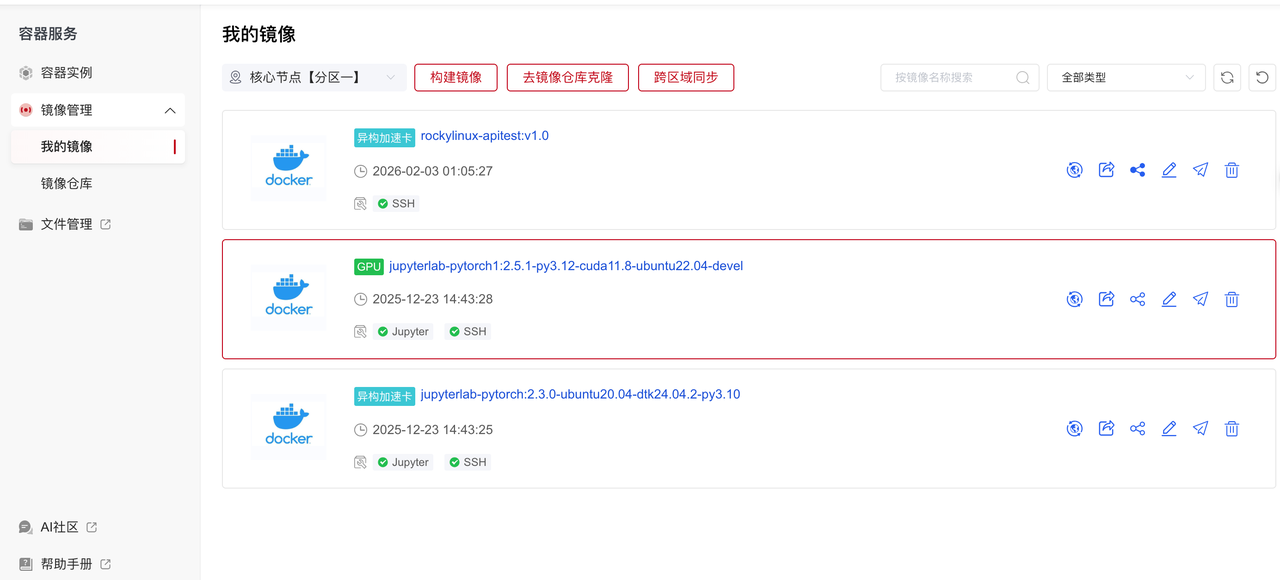 c. 加载镜像。租用新实例或者老实例选择更换镜像时,选择自己保存的镜像,这样即可恢复原来实例环境中所有内容。
c. 加载镜像。租用新实例或者老实例选择更换镜像时,选择自己保存的镜像,这样即可恢复原来实例环境中所有内容。 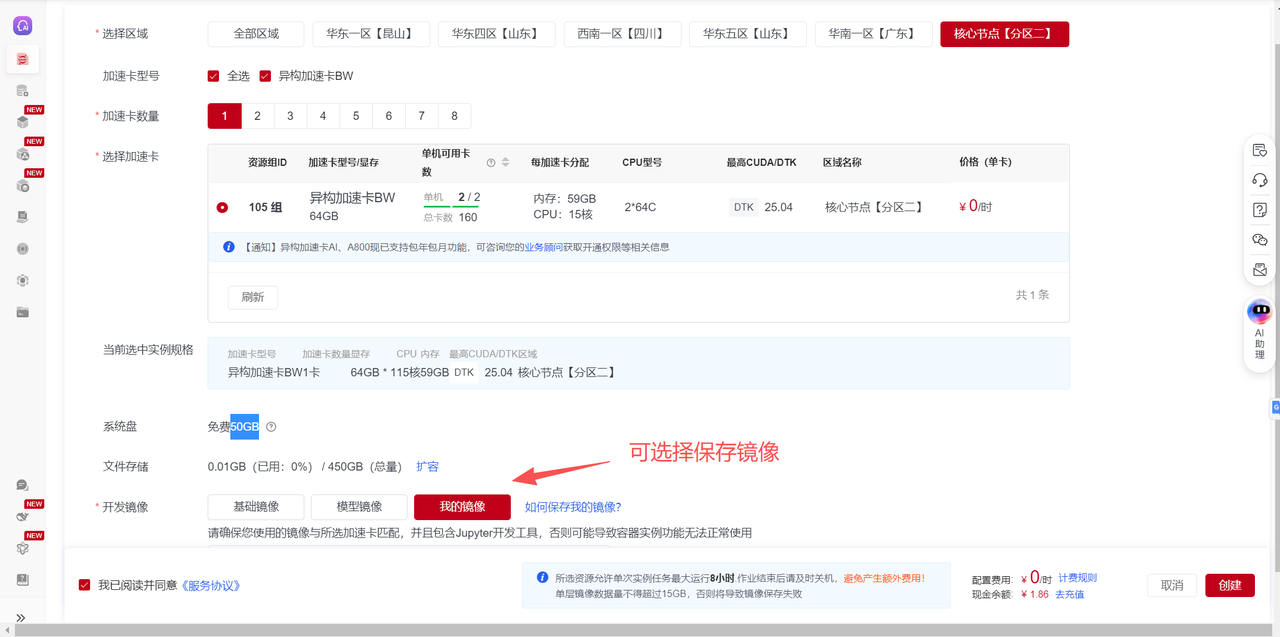
可以在关机时保存开发环境或使用“保存镜像”功能对开发环境进行备份,保证机器具有一致的环境和配置,满足再次启动环境、团队开发环境搭建、在其他平台复现环境等需求,容器实例开关机条件下皆可保存镜像。
注意: 为保证镜像正常运行,保存环境镜像时单层镜像数据量不得超过15 GiB,系统会对镜像大小进行校验,若镜像大小超过限额限制,您需要手动将容器环境下文件转移到文件存储中。
您可以使用如下代码快速定位当前环境中的大文件(含文件夹):
cd /
find . -path "./proc" -prune -o \
-path "/root/private_data/*" -prune -o \ ##排除个人文件
-path "/root/public_data/*" -prune -o \ ##排除平台共享文件
-path "/root/group_data/*" -prune -o \ ##排除团队共享文件
-path "/public/*" -prune -o \ ##排除共享存储文件
-path "/work/*" -prune -o \ ##排除共享存储文件
-type f -exec du -h {} + | sort -hr | head -n 20 ##展示大小排名前20的文件识别到大文件后,使用如下代码将文件迁移至文件存储永久保存:
mv /root/model_file /root/private_data/model_file迁移后文件可能无法在文件存储中使用(属主为root),您需要在当前环境中执行如下代码修改权限:
# 其中user_name需要替换为你的计算用户名
chown user_name:user_name /root/private_data/model_file保存镜像功能说明如下: 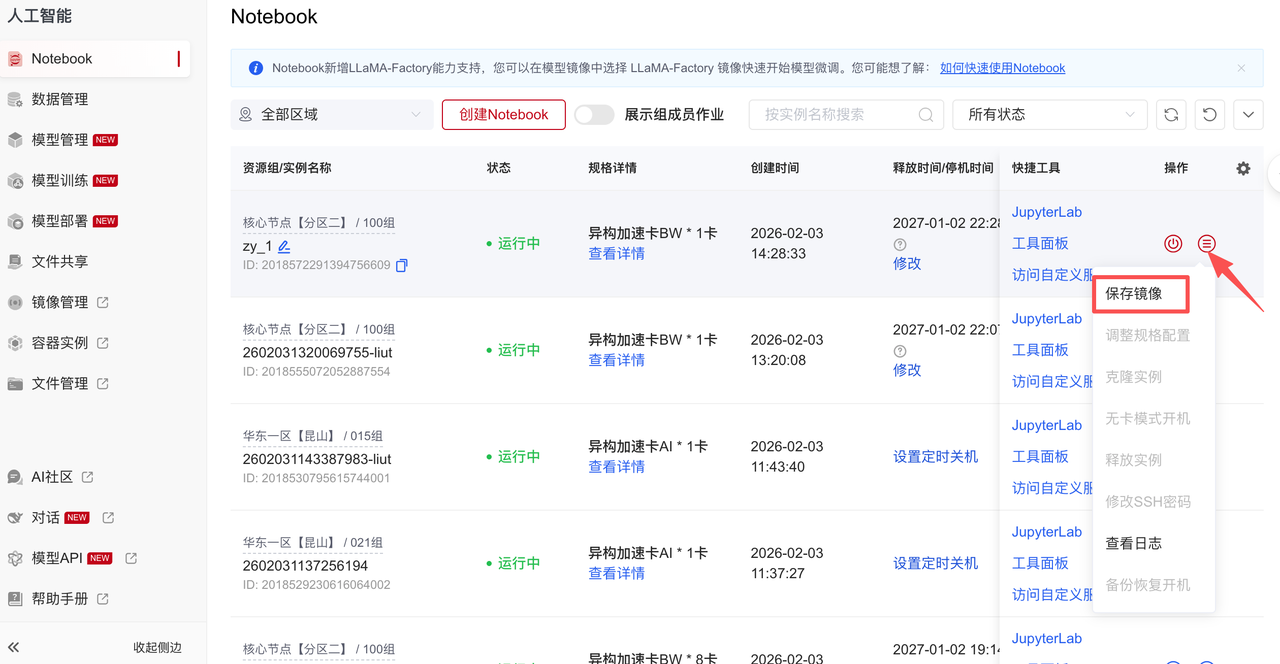 填写镜像名称和镜像标签以后默认将镜像保存到容器>我的镜像。
填写镜像名称和镜像标签以后默认将镜像保存到容器>我的镜像。 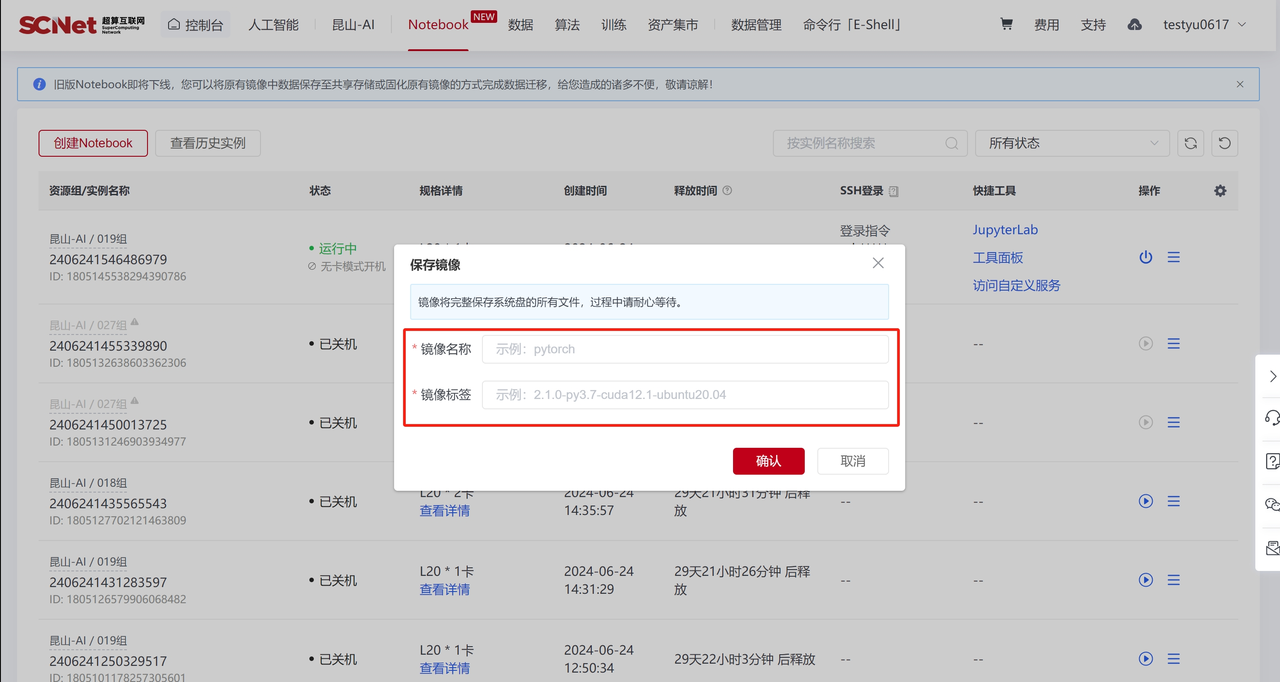 保存后的镜像可在“控制台>容器服务>镜像管理>我的镜像”中查看。
保存后的镜像可在“控制台>容器服务>镜像管理>我的镜像”中查看。 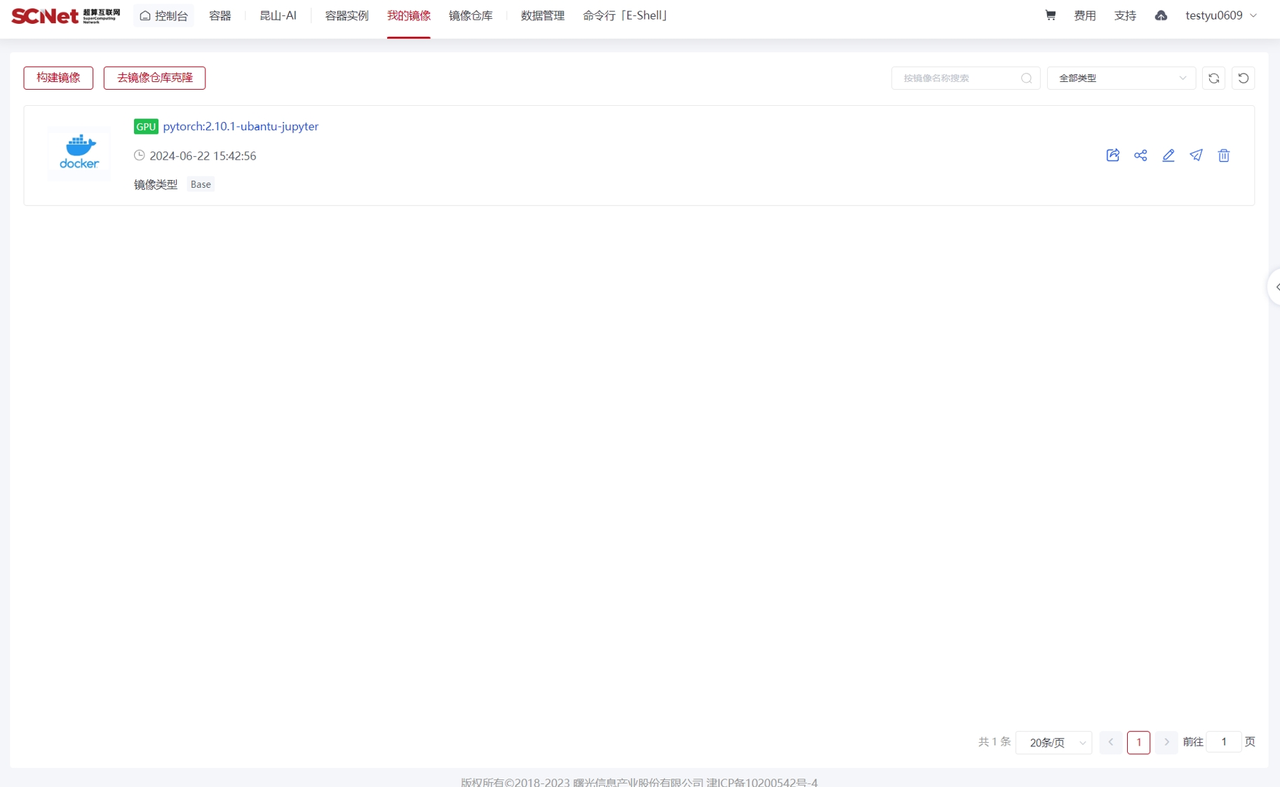
在Notebook界面可以使用“调整规格配置”功能增加或减少加速卡资源配置,此功能需在关机状态下使用。 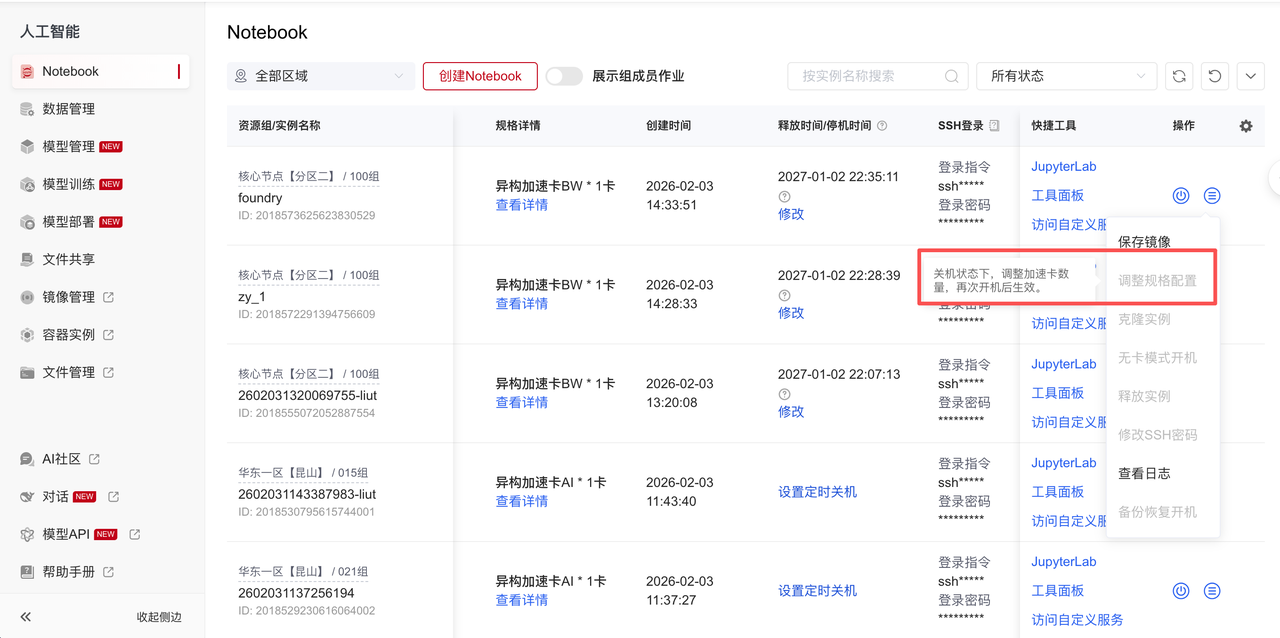
在Notebook界面可以使用“克隆实例”功能切换加速卡资源。 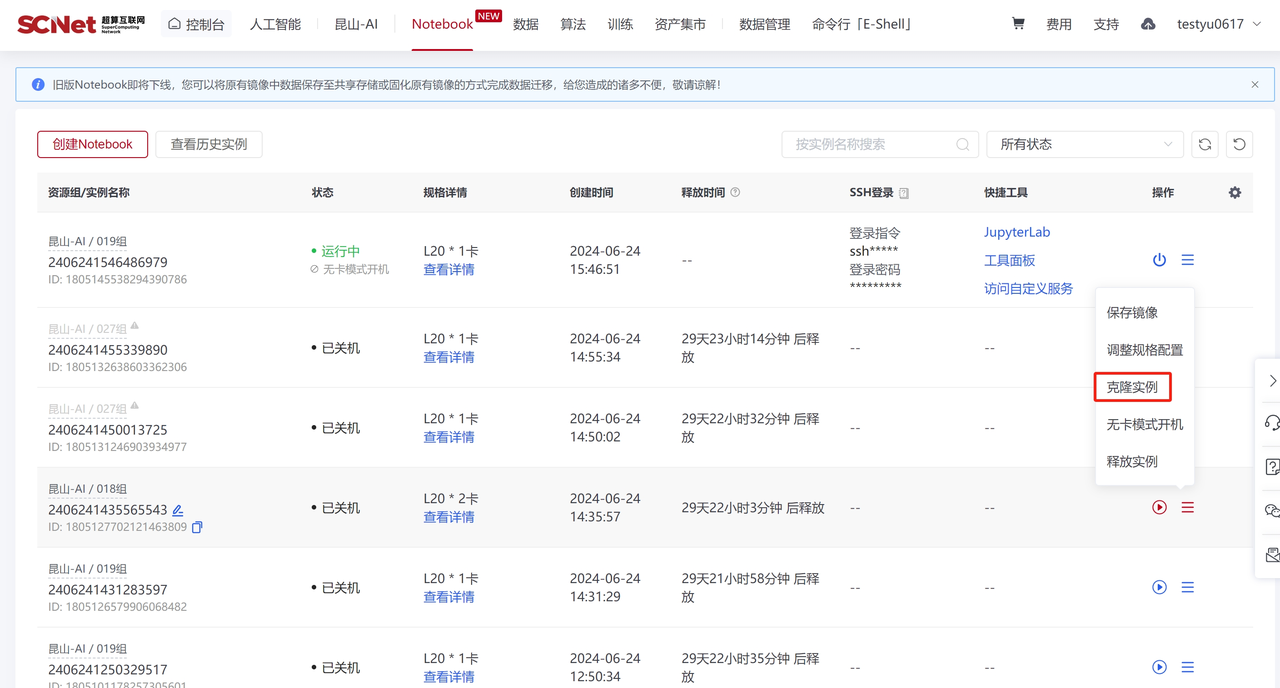
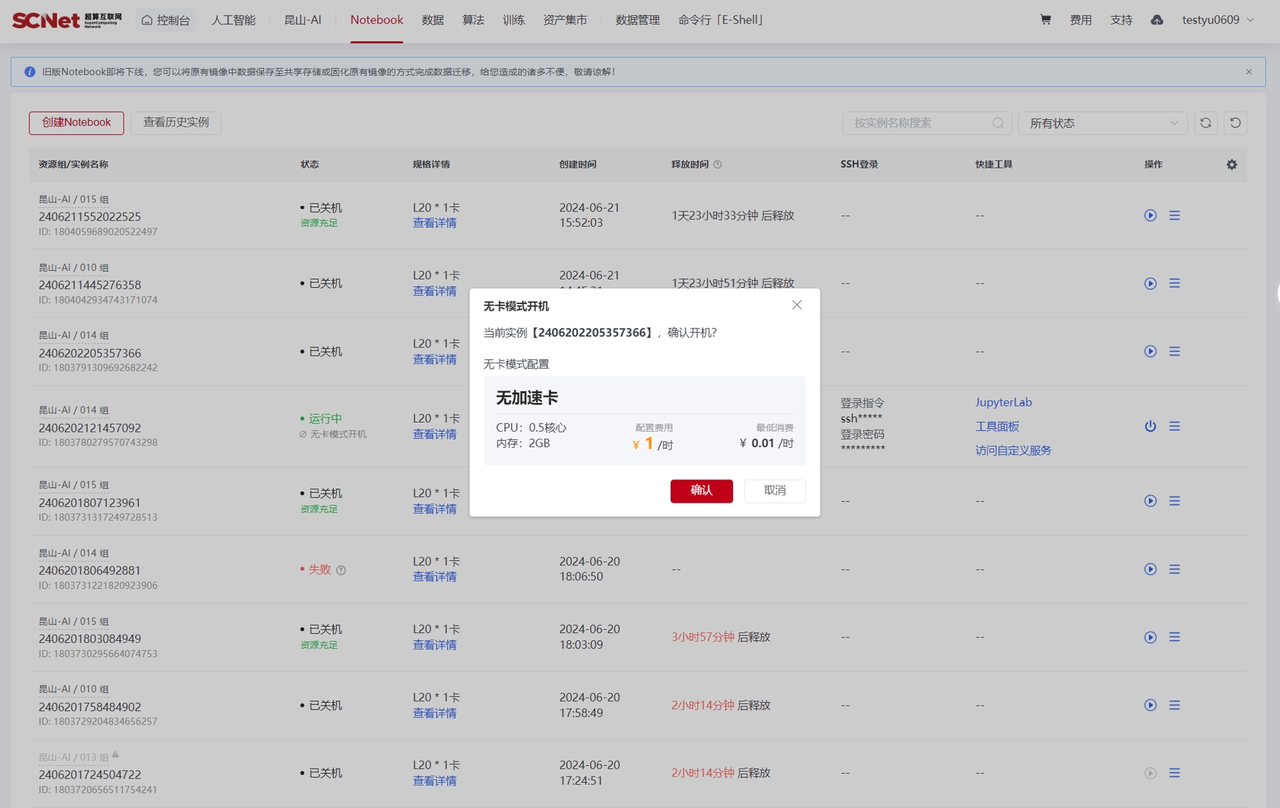
在Notebook界面可以使用“无卡模式开机”功能在加速卡资源不足或无需使用加速卡条件下,使用CPU资源启动容器实例进行操作。 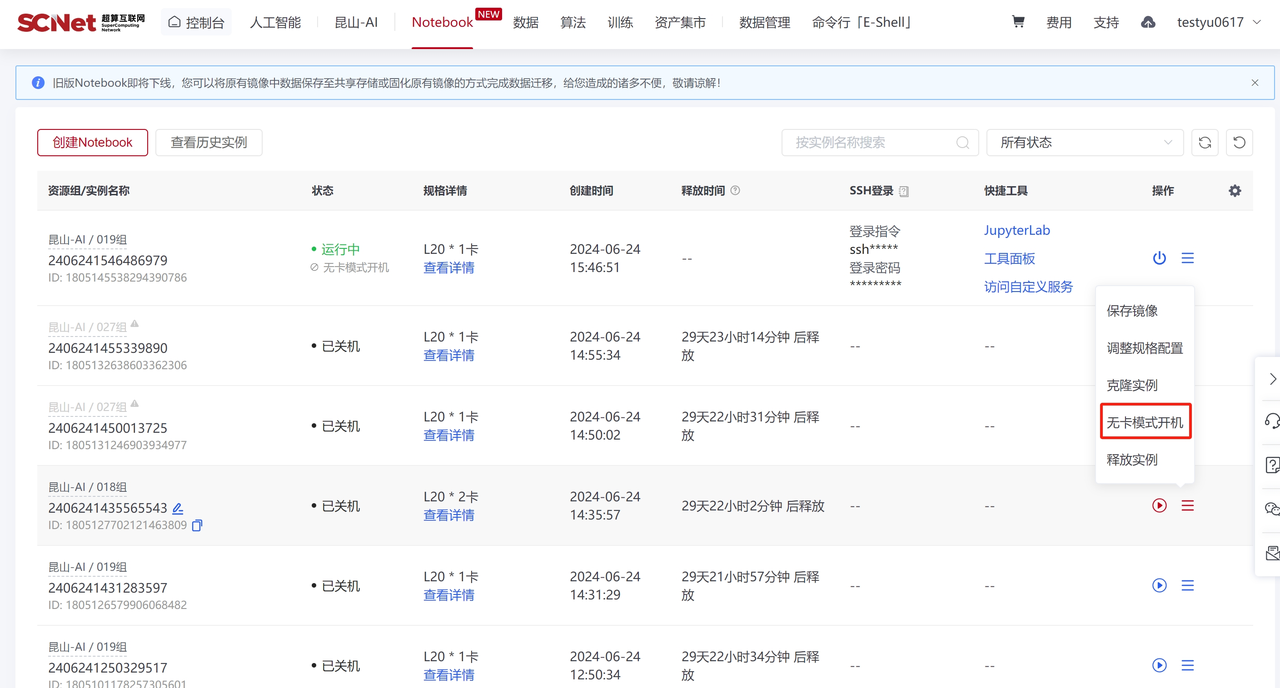
可以使用平台的文件管理进行上传,具体操作如下:
打开控制台>文件管理,参考如下图:
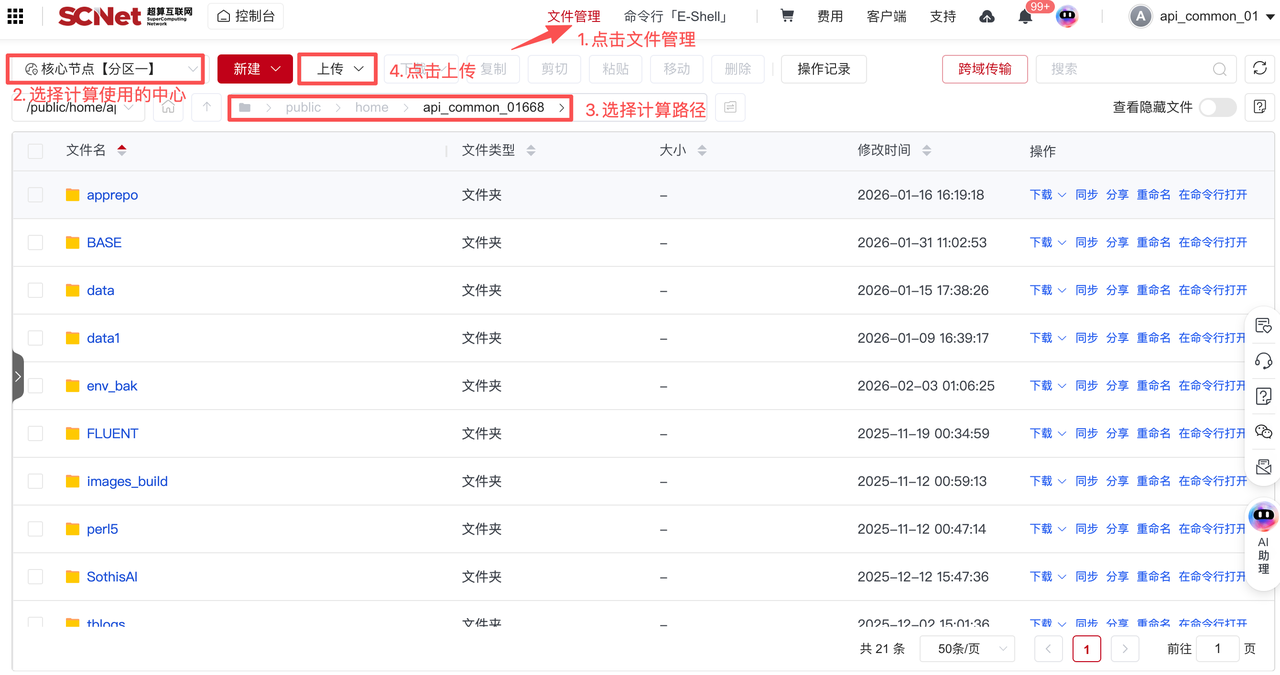
用户可以在个人家目录中安装anaconda或miniconda,并根据项目需求在login节点上进行conda环境的安装。
以yolo任务为例,2机16卡任务,numa绑定cpu核心和加速卡运行作业脚本可参考:(train.sh脚本调用single_processing.sh脚本)
#!/bin/bash
#SBATCH -J 16card-test
#SBATCH -p hxhdtest
#SBATCH -N 2
#SBATCH --ntasks-per-node=8
#SBATCH --cpus-per-task=16
#SBATCH --gres=dcu:8
#SBATCH --output=./logs/%j.out
module purge
module load compiler/dtk/25.04.2 mpi/hpcx/2.12.0/gcc-8.3.1
source /public/home/jsyadmin/miniconda3/bin/activate
conda activate yolov9
mkdir -p ./hostfiles ./logs
# ===== 修正:安全生成 hostfile =====
hostfile="./hostfiles/$SLURM_JOB_ID"
scontrol show hostnames "$SLURM_JOB_NODELIST" > "$hostfile"
# 使用 while read 逐行处理(避免空格问题)
> "./hostfiles/hostfile-dl-$SLURM_JOB_ID"
while IFS= read -r node; do
# 清理节点名(移除尾部空格/回车)
node=$(echo "$node" | tr -d '\r\n')
echo "${node} slots=8" >> "./hostfiles/hostfile-dl-$SLURM_JOB_ID"
done < "$hostfile"
np=$(( SLURM_NNODES * SLURM_NTASKS_PER_NODE )) # 16
nodename=$(head -1 "$hostfile" | tr -d '\r\n')
echo "[INFO] Hostfile content (hexdump):"
cat -A "./hostfiles/hostfile-dl-$SLURM_JOB_ID" # 检查不可见字符
# ===== 关键:添加 --oversubscribe 绕过 slots 检查 =====
mpirun -np $np \
--allow-run-as-root \
--hostfile "./hostfiles/hostfile-dl-$SLURM_JOB_ID" \
--bind-to none \
./single_processing.sh "$nodename"#!/bin/bash
# single_processing.sh - 安全自适应 NUMA 绑定(兼容 1/2/4/8 NUMA nodes)
lrank=$OMPI_COMM_WORLD_LOCAL_RANK
comm_rank=$OMPI_COMM_WORLD_RANK
comm_size=$OMPI_COMM_WORLD_SIZE
local_rank=$OMPI_COMM_WORLD_LOCAL_RANK
export LOCAL_RANK=$local_rank
export RANK=$OMPI_COMM_WORLD_RANK
export WORLD_SIZE=$OMPI_COMM_WORLD_SIZE
export MASTER_ADDR=$1
export MASTER_PORT=12321
export HIP_VISIBLE_DEVICES=$local_rank # 每进程独占1卡
# ===== SHCA网卡配置 =====
export NCCL_IB_HCA=shca_*
export NCCL_SOCKET_IFNAME=ib0
export NCCL_DEBUG=INFO
export NCCL_IB_TIMEOUT=23
export NCCL_IB_QPS_PER_CONNECTION=4
export HSA_FORCE_FINE_GRAIN_PCIE=1
export OMP_NUM_THREADS=1
export MIOPEN_FIND_MODE=3
export GPU_MAX_HW_QUEUES=4
#export UCX_IB_DEVICES=shca_0,shca_1,shca_2,shca_3
#export UCX_TLS=rc,sm,cuda_copy
#export UCX_NET_DEVICES=shca_$((local_rank / 2)):1 # 0,1→shca_0; 2,3→shca_1...
# ===== 自动检测可用 NUMA nodes =====
#NUMA_COUNT=$(numactl --hardware 2>/dev/null | grep -oP 'available: \K[0-9]+' || echo "1")
#HOSTNAME=$(hostname)
#echo "[DEBUG] Rank ${RANK}/${WORLD_SIZE} on ${HOSTNAME} | LOCAL_RANK=${local_rank} | NUMA_COUNT=${NUMA_COUNT}"
echo "start-------------------------------------"
echo numactl -s
APP="python -u train_dual.py --batch 32 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights yolov9-c.pt --name yolov9-c-$(date +%Y%m%d-%H%M%S) --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15"
export RANK=$comm_rank
export WORLD_SIZE=$comm_size
export MASTER_ADDR=${1}
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 # # 4,5,6,7 #,
case ${local_rank} in
[0])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=0 --membind=0 ${APP}
;;
[1])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=1 --membind=1 ${APP}
;;
[2])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=2 --membind=2 ${APP}
;;
[3])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=3 --membind=3 ${APP}
;;
[4])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=4 --membind=4 ${APP}
;;
[5])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=5 --membind=5 ${APP}
;;
[6])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=6 --membind=6 ${APP}
;;
[7])
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
numactl --cpunodebind=7 --membind=7 ${APP}
;;
esac进入项目路径,同时也是slurm脚本所在的文件夹,文件夹内包含输入文件和对应已经脚本,见下图(截图以yolov9项目为例): 
使用命令sbatch slurm脚本名提交作业。
sbatch train.slurm #脚本名可以换成自己的脚本名作业提交后会出现对应的作业号(下图数字),具体见下图:  3. 查看作业运行状态 使用命令squeue查看作业运行状态。
3. 查看作业运行状态 使用命令squeue查看作业运行状态。
squeue 4. 取消作业 先通过squeue查看JOBID,如上图JOBID为107404798,使用命令scancel JOBID取消作业。
4. 取消作业 先通过squeue查看JOBID,如上图JOBID为107404798,使用命令scancel JOBID取消作业。
scancel 107404798再次查看作业已经取消。 