AI类应用
>
模型部署
>
基于vllm框架的模型推理服务部署
第一步:创建Notebook基础镜像环境
登录超算互联网https://www.scnet.cn个人账号,点击右上角的“控制台”; 
1、点击快捷入口中的“Notebook”,进入创建Notebook页面; 
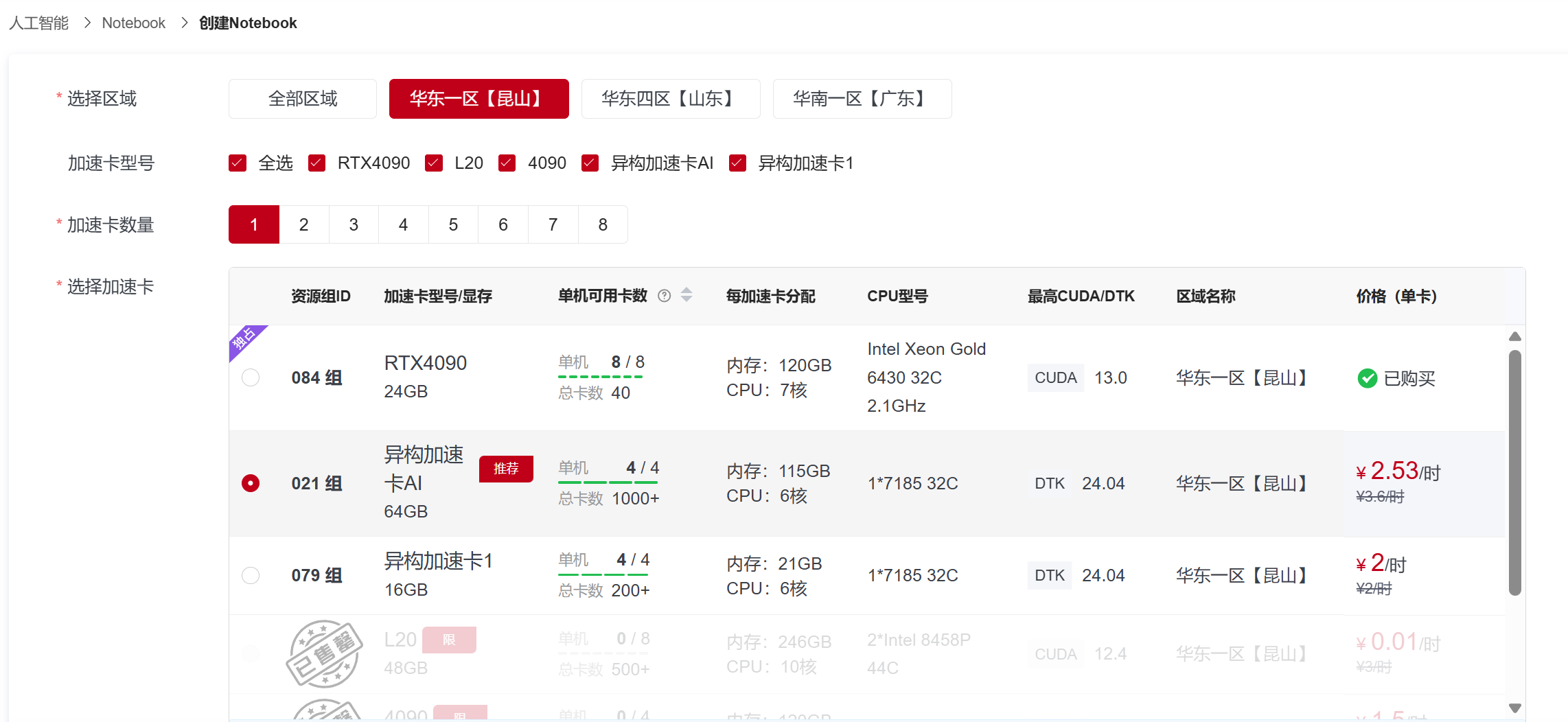
2、选择区域、异构加速卡AI-64GB,开发镜像中的“基础镜像”,在选择列表中选择
jupyterlab-pytorch:2.4.1-ubuntu22.04-dtk25.04.1-py3.10-devel 点击创建。

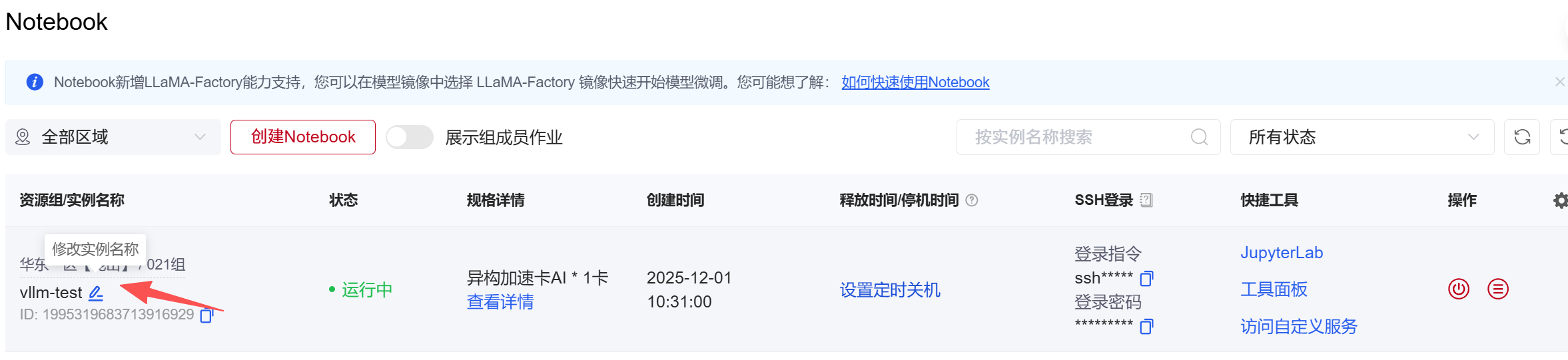
3、创建完成后,状态显示为”运行中“,自定义修改容器实例名称,点击快捷工具列的”JupyterLab“进入容器

4、进入容器,根据公告栏提示,将个人数据如模型文件、数据集等放在/root/private_data路径下。
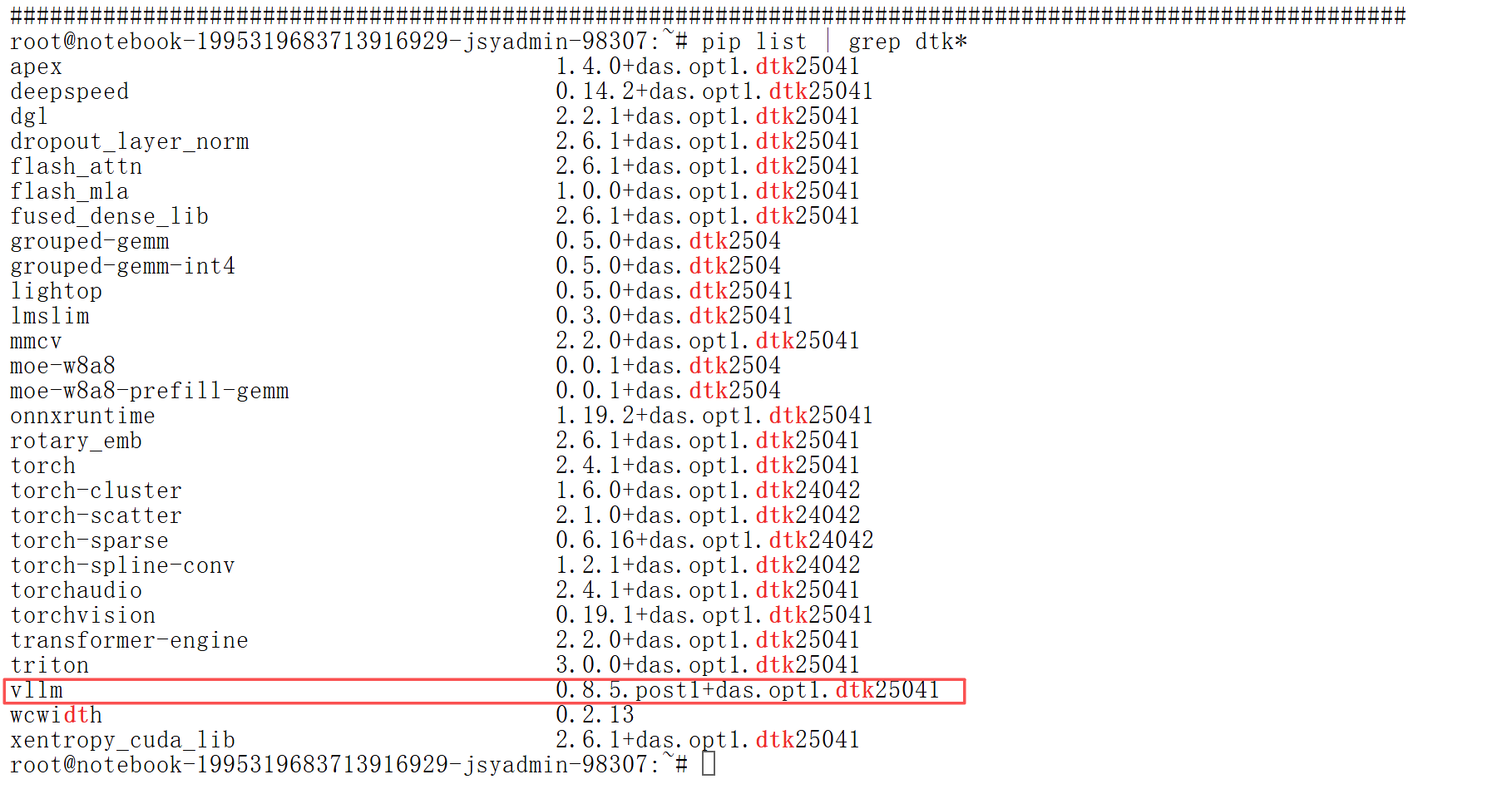
5、查看基础镜像配置的vllm版本
 以上就完成了基础环境的创建。
以上就完成了基础环境的创建。
1、登录超算互联网https://www.scnet.cn个人账号,点击”AI“社区
 2、点击”模型库“,搜索需要的模型文件,本文以 DeepSeek-R1-Distill-Qwen-7B为例
2、点击”模型库“,搜索需要的模型文件,本文以 DeepSeek-R1-Distill-Qwen-7B为例 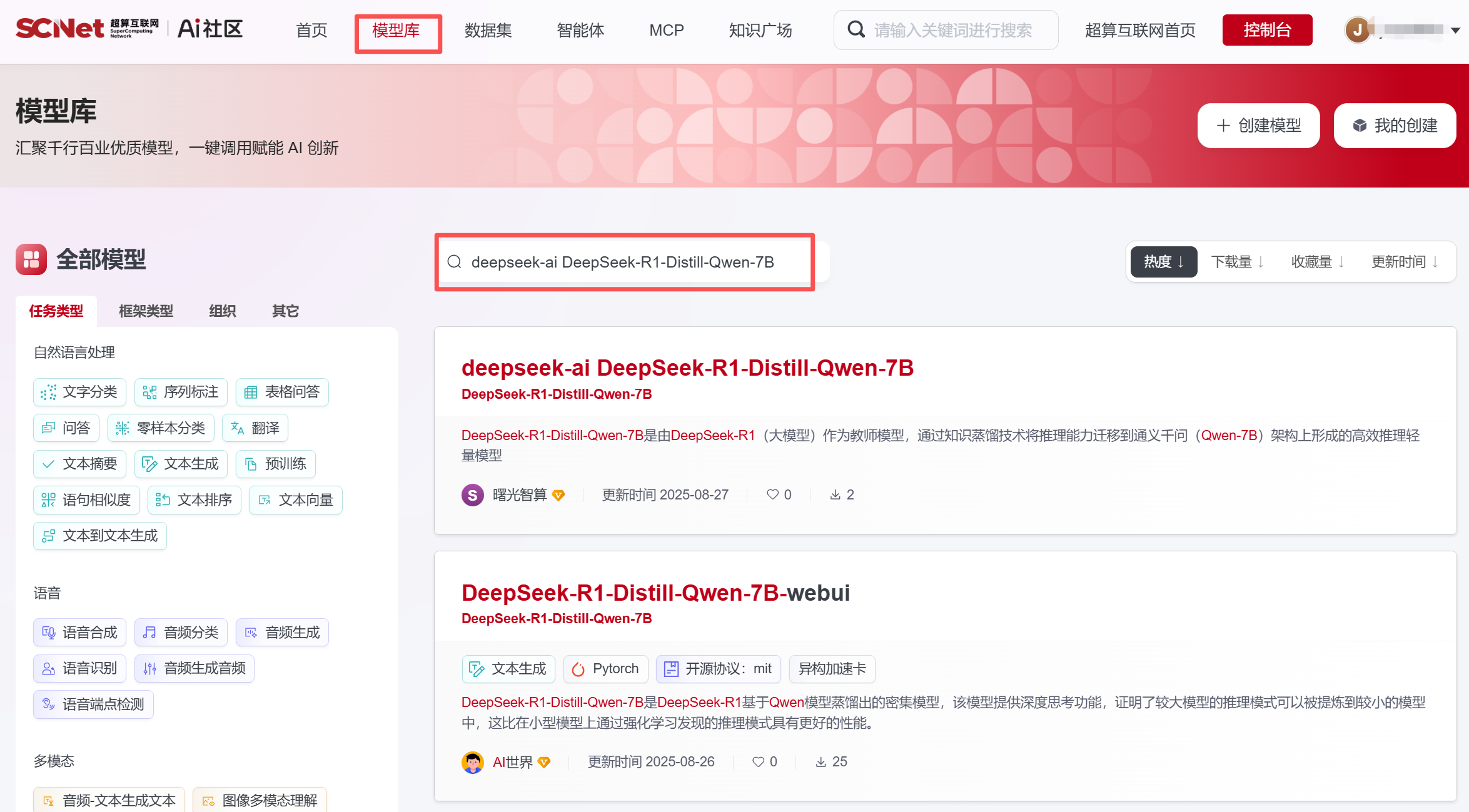 3、将模型文件”克隆至控制台“,选择对应的中心,复制克隆后的模型文件路径
3、将模型文件”克隆至控制台“,选择对应的中心,复制克隆后的模型文件路径 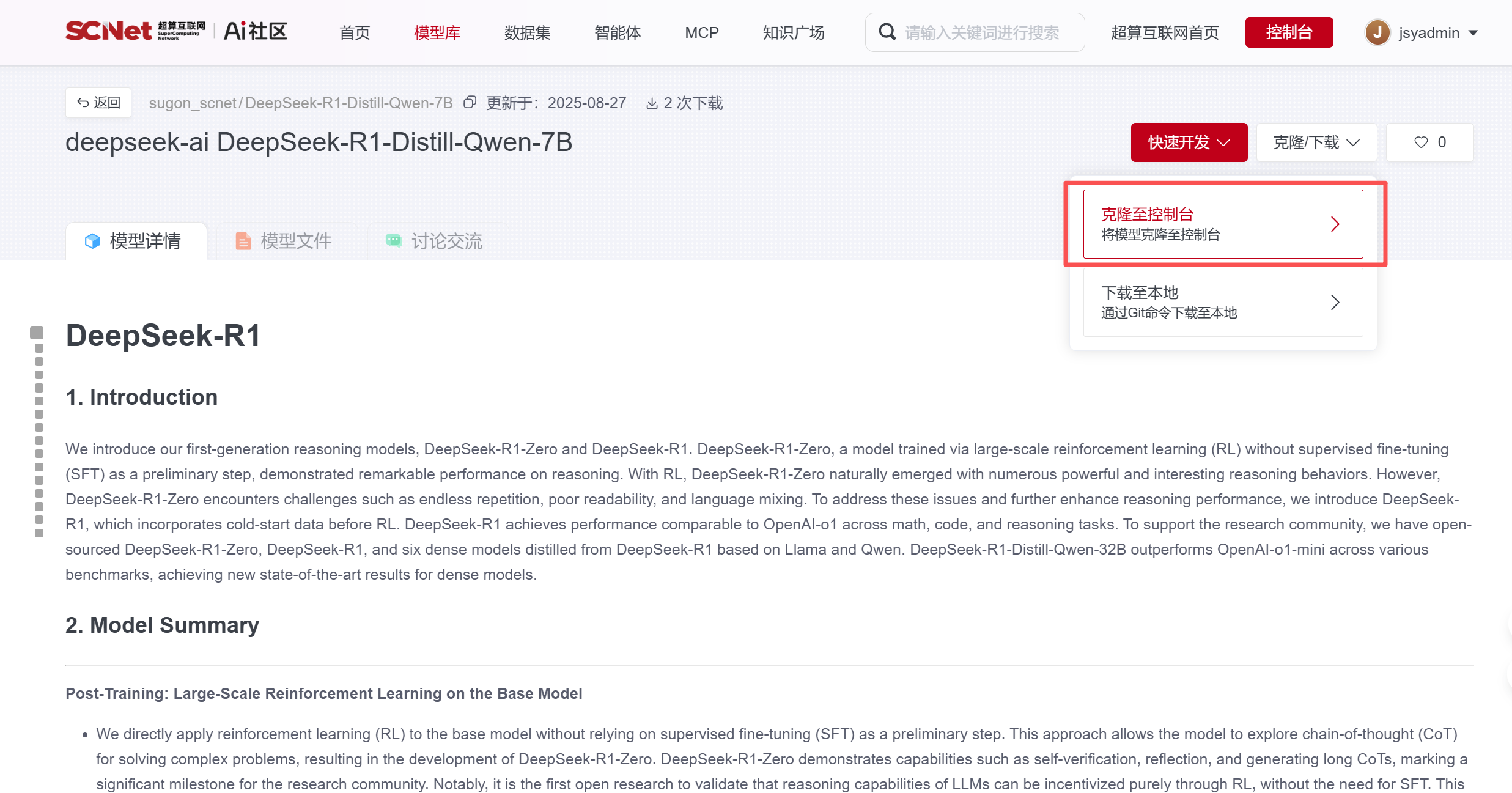
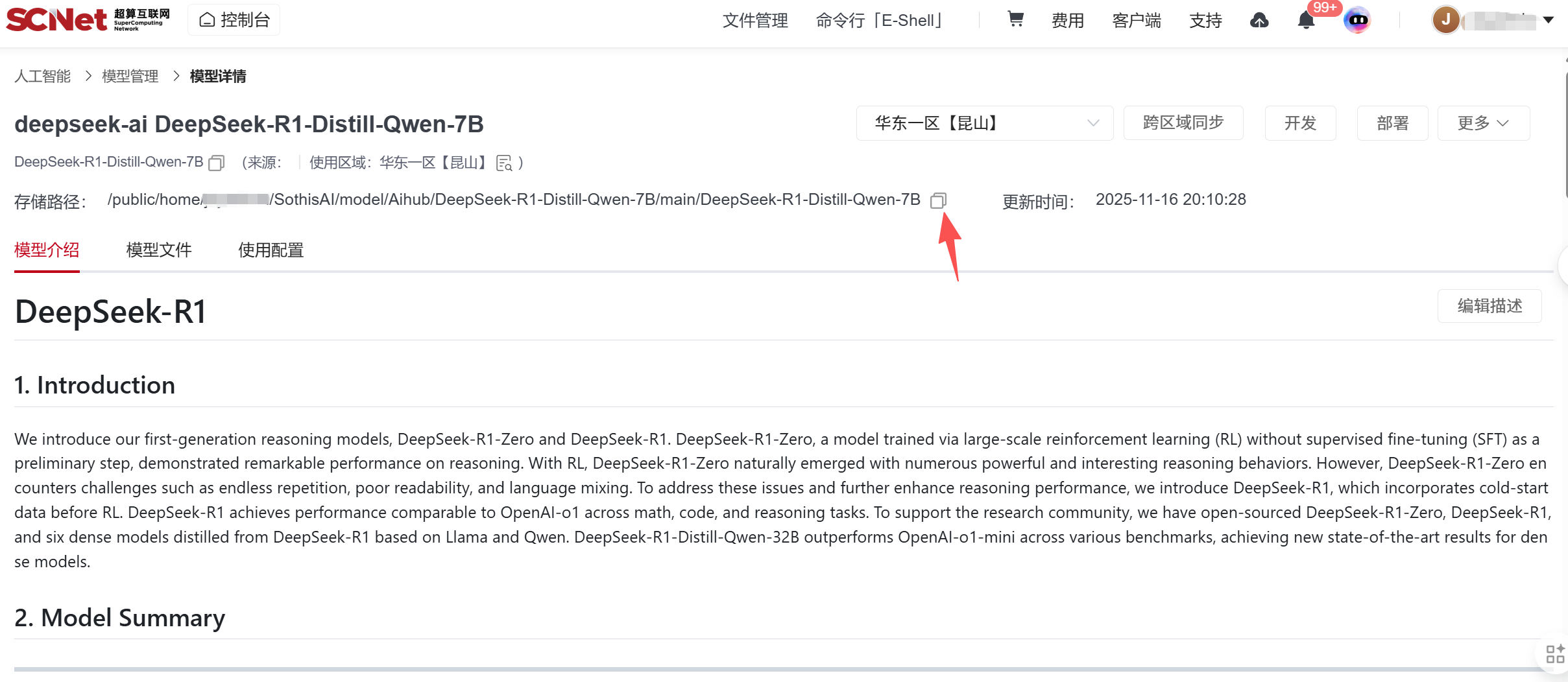
启动脚本
python3 -m vllm.entrypoints.openai.api_server \
--model /public/home/jsyadmin/SothisAI/model/Aihub/DeepSeek-R1-Distill-Qwen-7B/main/DeepSeek-R1-Distill-Qwen-7B/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--host 0.0.0.0 --port 10304 \
--gpu-memory-utilization 0.8 \
--served-model-name DeepSeek-R1-Distill-Qwen-7B \
--dtype bfloat16 \
--tensor-parallel-size 1 \
--max-model-len 5000 \
--trust-remote-code注:--module xxxx/xxx 模型路径 ;
--served-model-name xxx 自定义的模型名称 ;
--port xxx 自定义服务端口号;
--gpu-memory-utilization xxx 指定vllm可使用当前dcu的显存比例;
--dtype xxx 指定模型数据类型 ;
--tensor-parallel-size xxx 设置张量并行的大小,即dcu的数量;
--max-model-len xxx 指定模型能够处理的最大输入长度;
运行脚本
nohup sh vllm.sh > vllm_log.txt &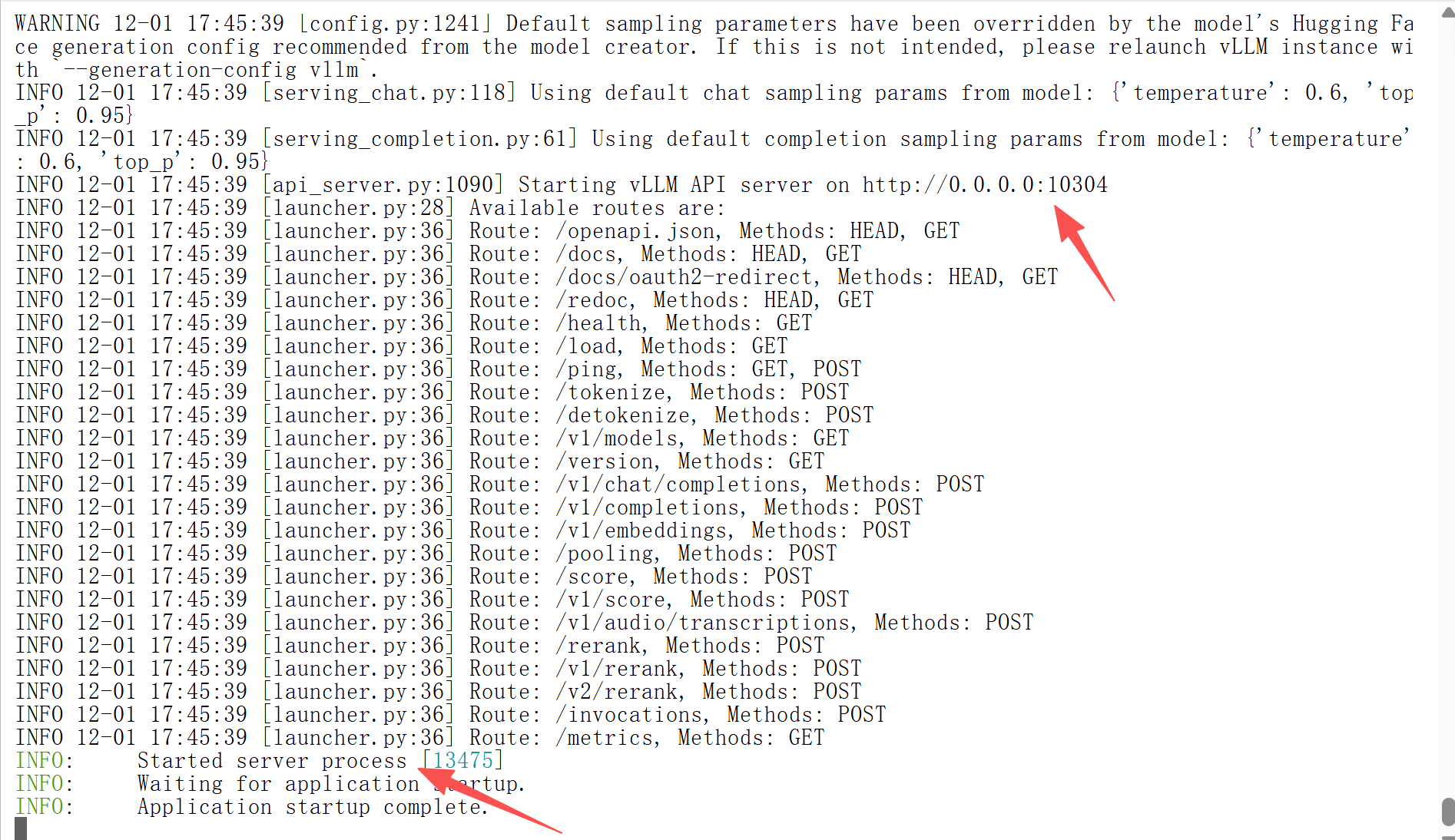 本地验证
本地验证
curl http://127.0.0.1:10304/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "DeepSeek-R1-Distill-Qwen-7B","messages": [{"role": "user", "content": "请介绍下西安,要求500字以内"}]}' 注:http://xxxx:port/v1/chat/completions , 其中xxx为localhost;
注:http://xxxx:port/v1/chat/completions , 其中xxx为localhost;
port 为自定义的端口号;
"model":"xxxxxx" ,为served-model-name 自定义的模型名;
1、保存镜像为jupyterlab-pytorch-vllm-test 
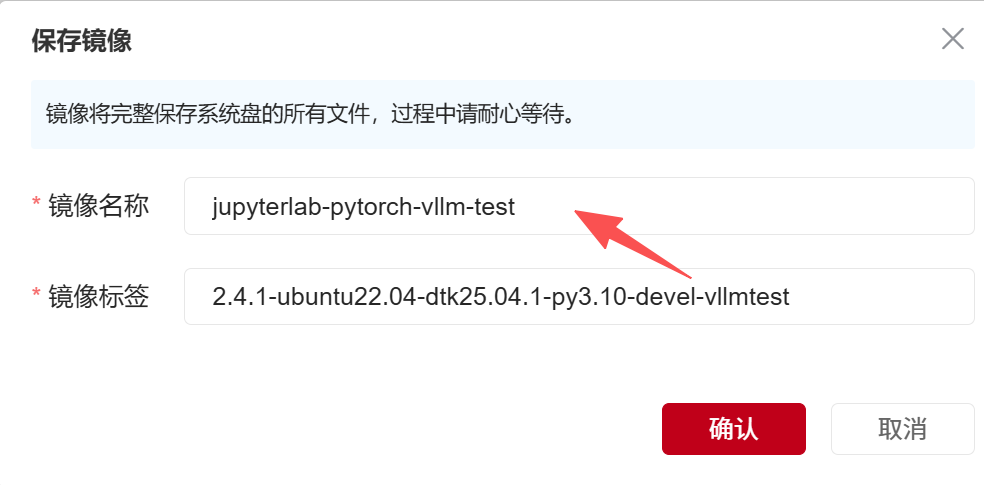 镜像保存后,跳转到我的镜像查看保存进度,等待镜像保存完成。
镜像保存后,跳转到我的镜像查看保存进度,等待镜像保存完成。  此处我们基于异构加速卡AI的模型镜像保存镜像,镜像带有异构加速卡的标签。
此处我们基于异构加速卡AI的模型镜像保存镜像,镜像带有异构加速卡的标签。
注意,镜像处于“保存中”状态时不要关闭Notebook实例,等待镜像保存完成后即可关机。
2、点击人工智能服务中的“模型部署”,并选择自定义创建。 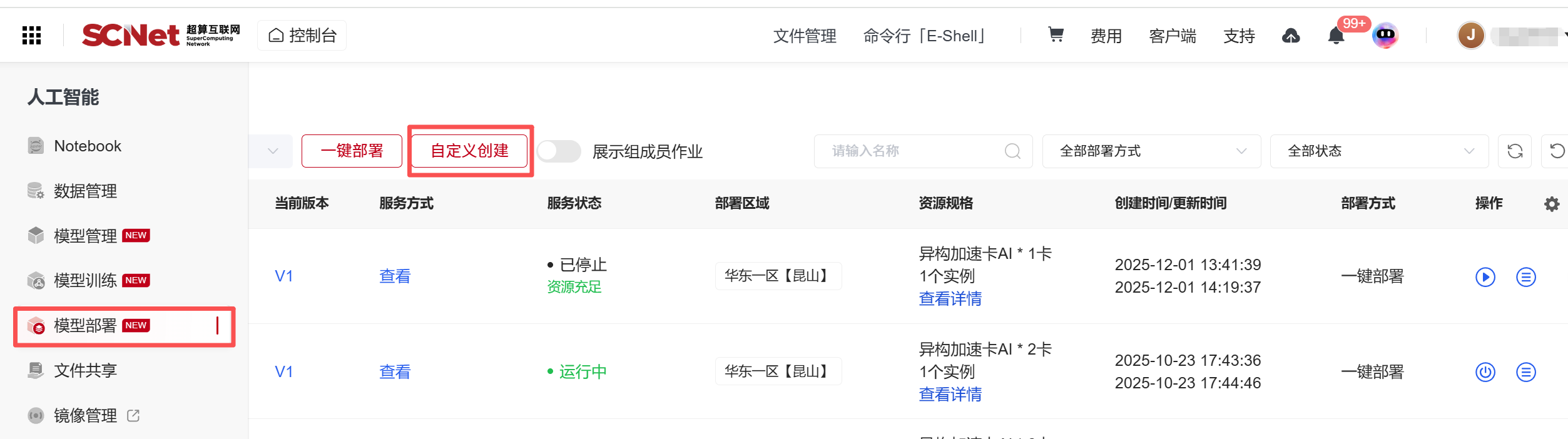 在部署页面,选择部署区域华东一区【昆山】。填写“服务名称”、并在“从镜像中选择”中填写“镜像名称”和对应的“启动命令”。服务方式选择“API调用地址”,填入服务端口号“10304”。
在部署页面,选择部署区域华东一区【昆山】。填写“服务名称”、并在“从镜像中选择”中填写“镜像名称”和对应的“启动命令”。服务方式选择“API调用地址”,填入服务端口号“10304”。
启动命令为:
cd /root/private_data/liyongdan/yongdantest && sh vllm.sh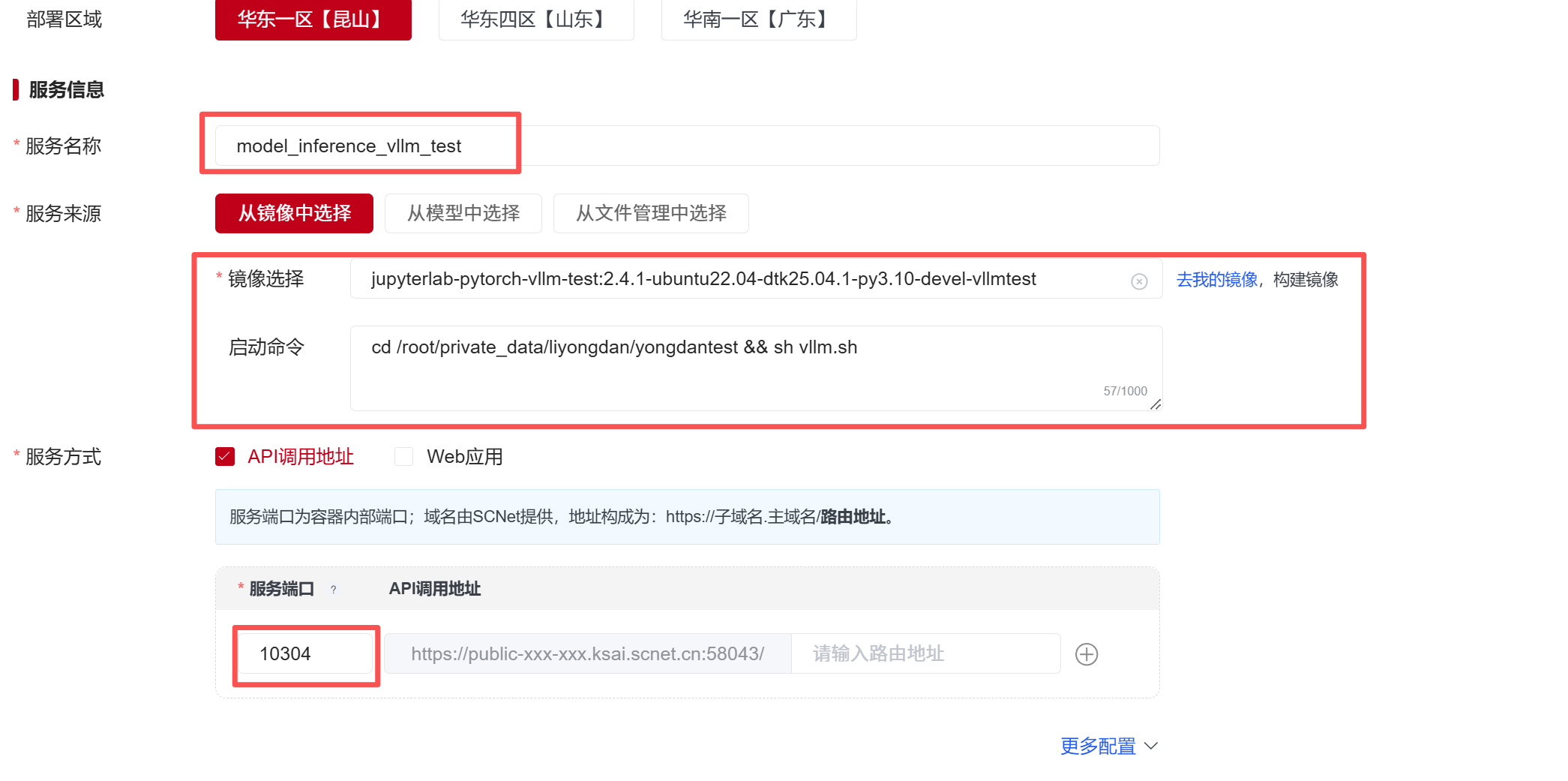 随后选择资源,这里我们选择异构加速卡AI-64GB,点击“创建”即可部署服务。
随后选择资源,这里我们选择异构加速卡AI-64GB,点击“创建”即可部署服务。 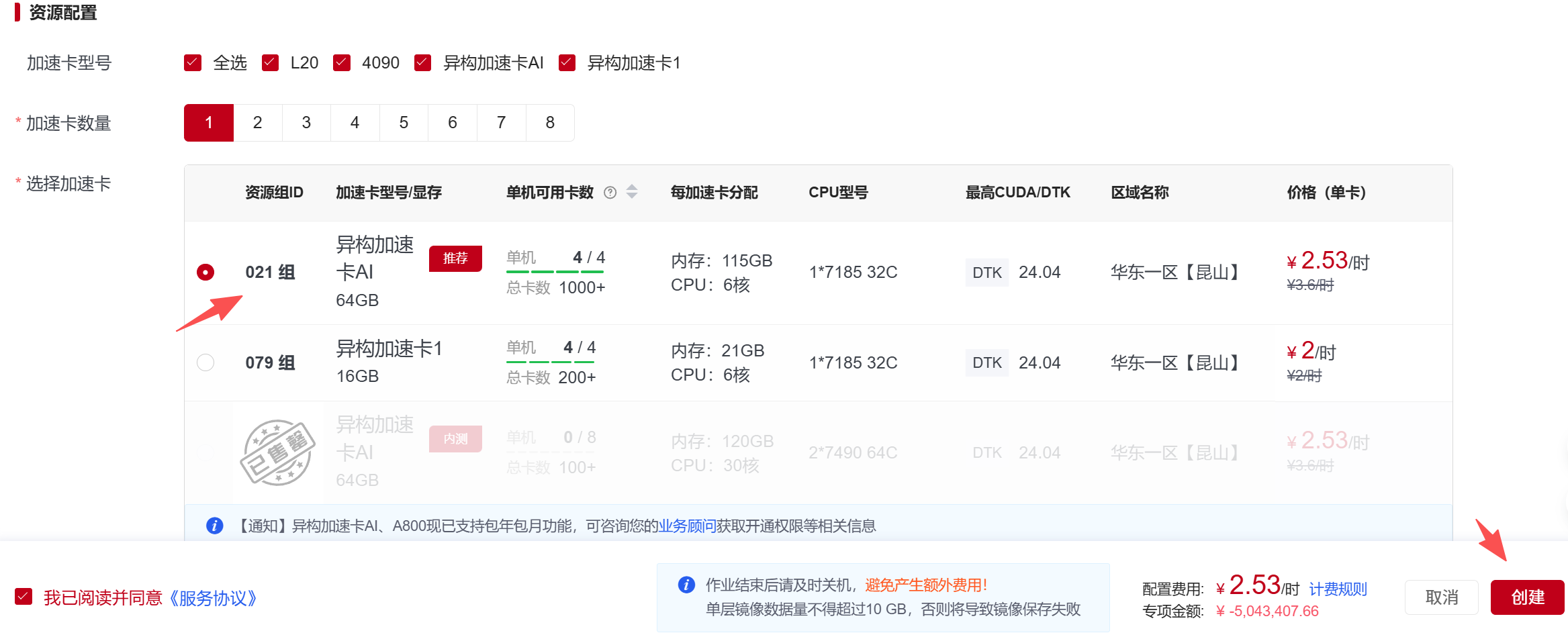 等待镜像拉取时,服务状态显示为部署中;开始运行启动代码时,状态显示为运行中。
等待镜像拉取时,服务状态显示为部署中;开始运行启动代码时,状态显示为运行中。 
部署过程中,可以点击最右侧按钮,选择“查看日志”,查询服务的部署日志与部署状态,也可选择“部署事件”查看镜像拉取状态。 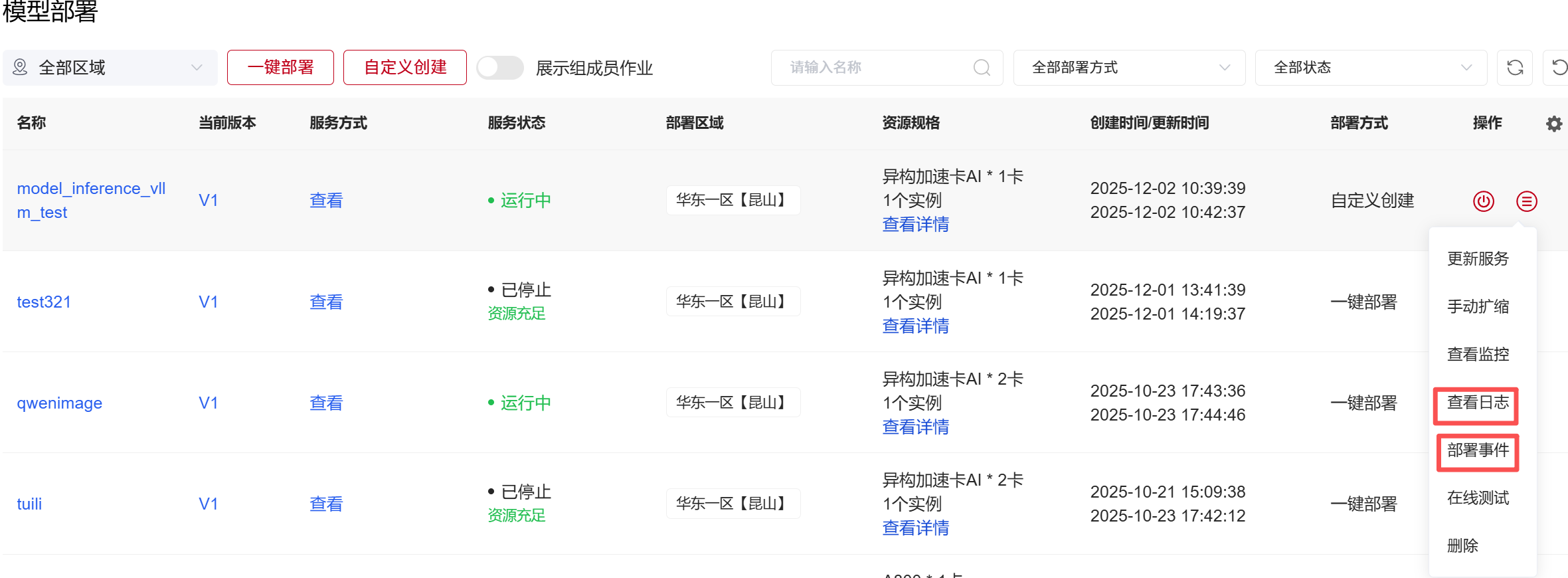 查看服务日志信息
查看服务日志信息  查看服务监控面板
查看服务监控面板 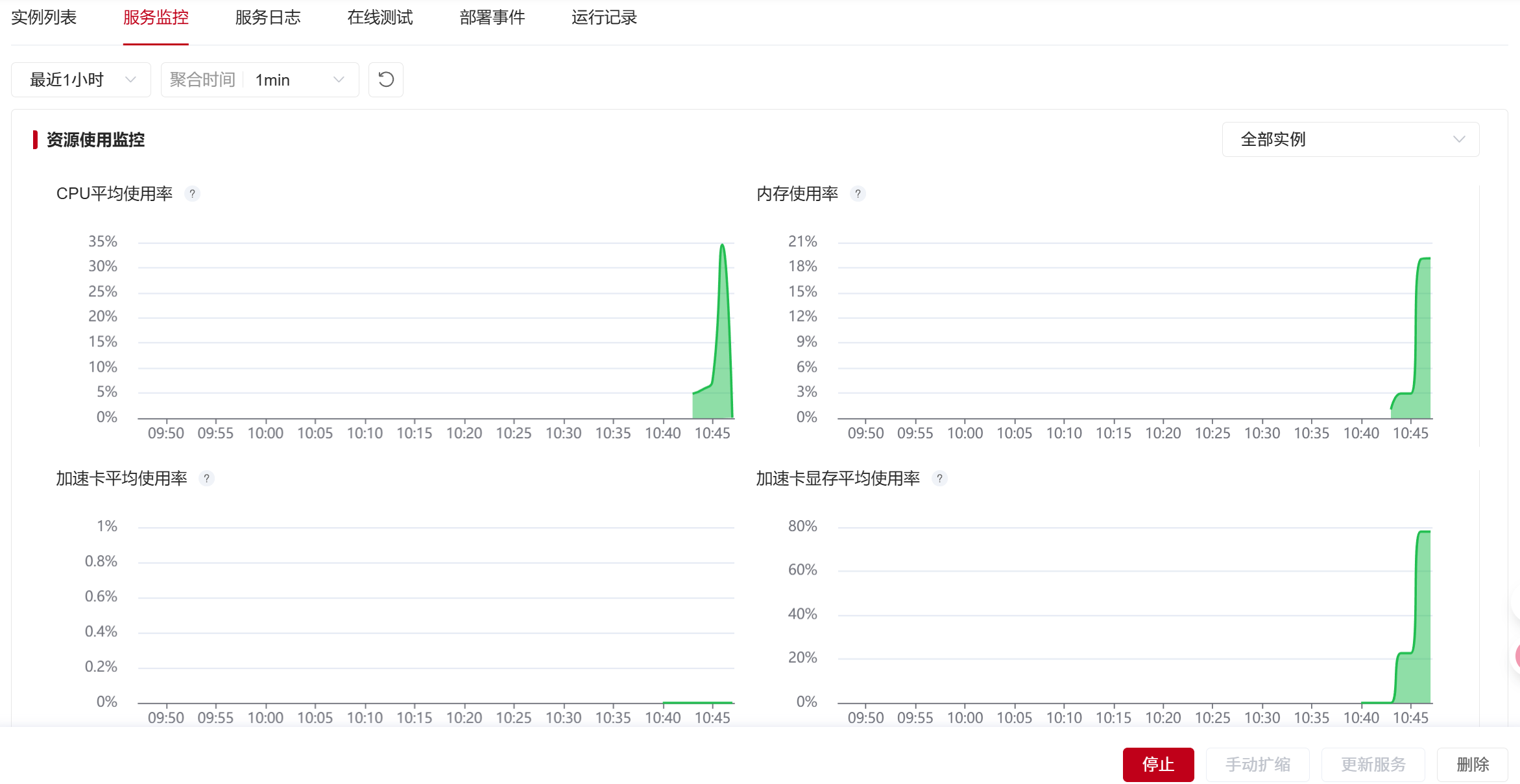 点击”在线测试“,测试服务可用性
点击”在线测试“,测试服务可用性  查看服务方式,复制API调用地址,本地通过postman等第三方工具,调用模型服务
查看服务方式,复制API调用地址,本地通过postman等第三方工具,调用模型服务 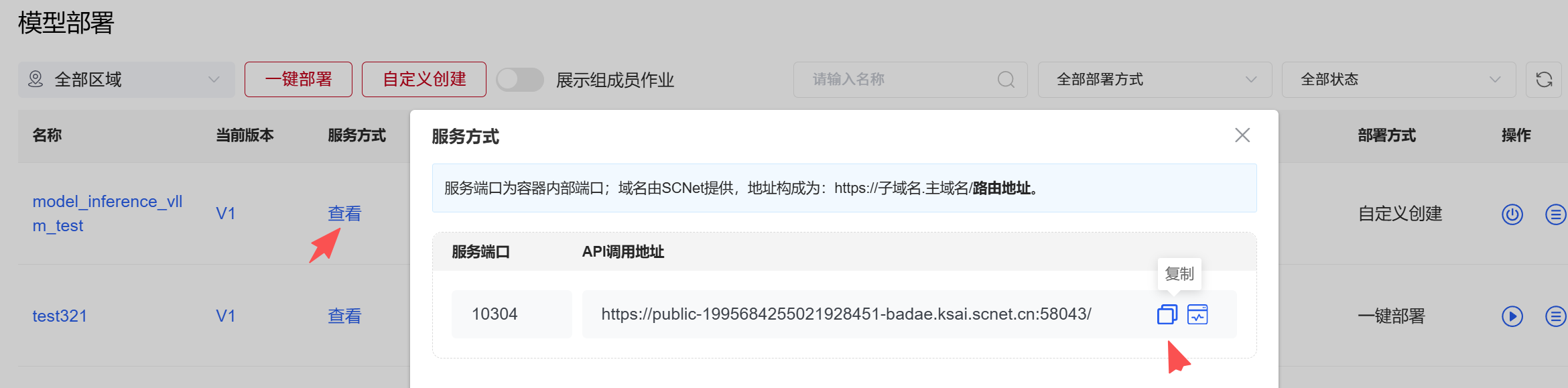
以上就完成了,在超算互联网平基于vllm推理框架的基础镜像,部署一个可以本地调用的模型推理服务。