核心节点用户手册
>
系统简介
本章节会针对核心节点的具体情况做一个简单的介绍,主要包括计算资源、存储资源、网络资源、基础环境、调度系统。
| 资源方式 | 产品 | 资源名称 | 资源名称 |
|---|---|---|---|
| K8S | Notebook模型部署模型训练 | 异构加速卡BW 显存64GB | 128核|2.5GHz|512GB内存|BW*8|400Gb |
| Slurm | 共享独占容器实例/命令行 | 异构加速卡BW 显存64GB | 128核|2.5GHz|512GB内存|BW*8|400Gb |
| 资源名称 | 资源编号 | 资源规格 | 资源型号 | 容量 | 性能指标 |
|---|---|---|---|---|---|
| 高IO存储-1 | P300S-SSD | 随容量线性扩展/毫秒级/SSD/SSD | NVME文件存储 | 80PB | 300万IOPS/套- |
| 分布式文件存储-2 | P300S-SATA | 随容量线性扩展/毫秒级/分布式文件存储/HDD/HDD | HDD文件存储 | 80PB | 80GB/s |
| 对象存储-1 | P300S-SATA | 随容量线性扩展/毫秒级/分布式文件存储/HDD/HDD | HDD对象存储 | 14PB | 40GB/s |
网络通信方面,集群采用全线速、无阻塞的 400Gb 专用计算网络,是目前最先进的通信网络,能极大提升计算的速度和扩展性。
核心节点【分区】内置了基础环境,包括操作系统、编译器、MPI以及集群管理工具,提供集群的基础使用和管理功能,具体可参考下表(部分列出,更详细的预制环境可使用module avail查看):
| 分类 | 软件名 | 版本 | 路径 | 加载方式 | 说明 |
|---|---|---|---|---|---|
| 操作系统 | CentOS | 8.4 | - | 默认加载 | 企业级操作系统 |
| 集群管理 | 集群综合管理系统 | 5.0 | /opt/grideview | 默认加载 | HPC集群综合管理系统 |
| 编译器 | GNU编译器 | 4.8.5 | /usr/bin | 默认加载 | GNU编译器 |
| Intel编译器(含MKL库及所有套件) | 2021.3.0 | /public/software/compiler/intel-compiler/2021.3.0/ | module | Intel编译器 | |
| Intel oneapi | 2024.0.1 | /public/software/compiler/intel/neapi/oneapi-2024.0.1/ | module | Intel编译器 | |
| cmake | 3.26.4 | /usr/bin | 默认加载 | cmake编译器 | |
| PGI编译器 | 20.9 | /public/software/compiler/nvidia/hpc_sdk/Linux_x86_64/20.9/ | module | PGI编译器 | |
| MPI | openmpi-gnu | 4.1.5 | /public/software/mpi/openmpi/openmpi-4.1.5/ | module | GNU版openmpi |
| openmpi-intel | 3.1.4 | /public/software/mpi/openmpi/3.1.4/ | module | Intel版openmpi | |
| intelmpi | 2021.3.0 | /public/software/mpi/intelmpi/2021.3.0/ | module | Intel mpi |
核心节点支持slurm和k8s两种调度,Notebook产品使用k8s调度,命令行使用slurm调度,下面将主要介绍一下slurm调度和其常用命令。
SLURM是一款开源的集群管理和作业调度系统,专为大规模计算集群设计。 该系统具备强大的监控功能,能够实时跟踪作业进度、资源使用情况以及节点健康状态,并提供详细的作业和资源使用报告,帮助用户及时了解作业运行和集群资源使用的情况。此外,SLURM 还支持作业依赖管理,方便用户根据需求高效调度复杂的计算任务。 Slurm 提供了一系列命令,用于查询和管理作业及节点状态,以帮助用户高效地利用集群资源。常用的 slurm 调度命令及简要说明如下:
| 常用命令 | 说明 |
|---|---|
| sinfo | 查看节点或集群状态 |
| squeue | 查看作业排队状态 |
| srun | 提交交互式作业 |
| sbatch | 提交批处理作业 |
| scontrol | 查看和控制作业和节点状态 |
| sacct | 显示作业的记账信息 |
| scancel | 取消作业 |
该命令可以查询节点和队列的状态,常见选项如下:
sinfo 命令常用选项说明 :
| --all | 查看所有分区信息 |
| --help | 查看 sinfo 命令帮助信息 |
| --long | 查看分区详细信息 |
| --node | 查看节点信息 |
| --partition | 查看指定分区信息 |
| --state | 查看指定状态的节点 |
sinfo 用于查询集群的资源使用情况,包含节点和队列的状态等信息,示例如下:  其中,PARTITION 表示分区、NODES 表示节点数、NODELIST 表示节点列表、STATE 表示节点运行状态。
其中,PARTITION 表示分区、NODES 表示节点数、NODELIST 表示节点列表、STATE 表示节点运行状态。
集群分区状态包含 UP(正常)、DOWN(接收不调度)、DRAIN(调度不接收)和 INACTIVATE(DOWN+DRAIN,不接收不调度)。节点常见状态有 drain(下线),alloc(已分配),idle(空闲),down(故障),mix(已分配,但未占满)。状 态 drain 和 down 的区别在于:drain 常用于维护或者检查期间临时下线节点,正 在运行的作业不受影响,后续作业暂时无法提交至该节点。Down 状态表示节点完全不可用,通常用于需要下架维修的故障。
该命令用于查询作业状态,返回当前运行和排队的作业信息,常见选项如下:
squeue 命令常用选项说明 :
| --help | 查看 squeue 命令帮助信息 |
| --jobs <job_id_list> | 查看指定 JOB ID 的信息 |
| --name | 查看指定名称的作业信息 |
| --partition | 查看指定分区的作业信息 |
| --priority | 按照优先级查看作业信息 |
| --state | 指定状态查看作业信息 |
| --users | 指定用户名称查看作业信息 |
使用 squeue 命令查看用户作业信息,示例如下: 其中,JOBID 是调度系统分配给作业的唯一标识符,PARTITION是作业分区,NAME是作业的名称,USER是提交作业的用户名,ST表示作业当前的状态,TIME是作业已经运行的时间,NODES是作业占用的节点数,NODELIST是作业运行的节点列表。
其中,JOBID 是调度系统分配给作业的唯一标识符,PARTITION是作业分区,NAME是作业的名称,USER是提交作业的用户名,ST表示作业当前的状态,TIME是作业已经运行的时间,NODES是作业占用的节点数,NODELIST是作业运行的节点列表。
常见的作业状态包括:R(正在运行),PD(等待资源), CG(作业正在完成中),CA(作业被取消),CD(作业已完成),F(作业运行失 败),NF(节点问题导致作业失败),PR(作业被抢占),S(作业被挂起),TO (作业超时被终止)。
该命令可以查询作业、节点和分区状态、设置作业的优先级、控制作业状态 (如恢复、暂停或取消)等。
scontrol 命令常用选项说明 :
| --help | 查看 scontrol 命令帮助信息 |
| show job | 查看指定作业 ID 的详细信息 |
| show nodes | 查看指定节点的详细信息 |
| show partition | 查看集群中所有分区的状态和配置信息 |
| update | 更新作业或节点的状态,比如重新配置作业的优先级 |
使用 scontrol 查看节点详细信息,示例如下: 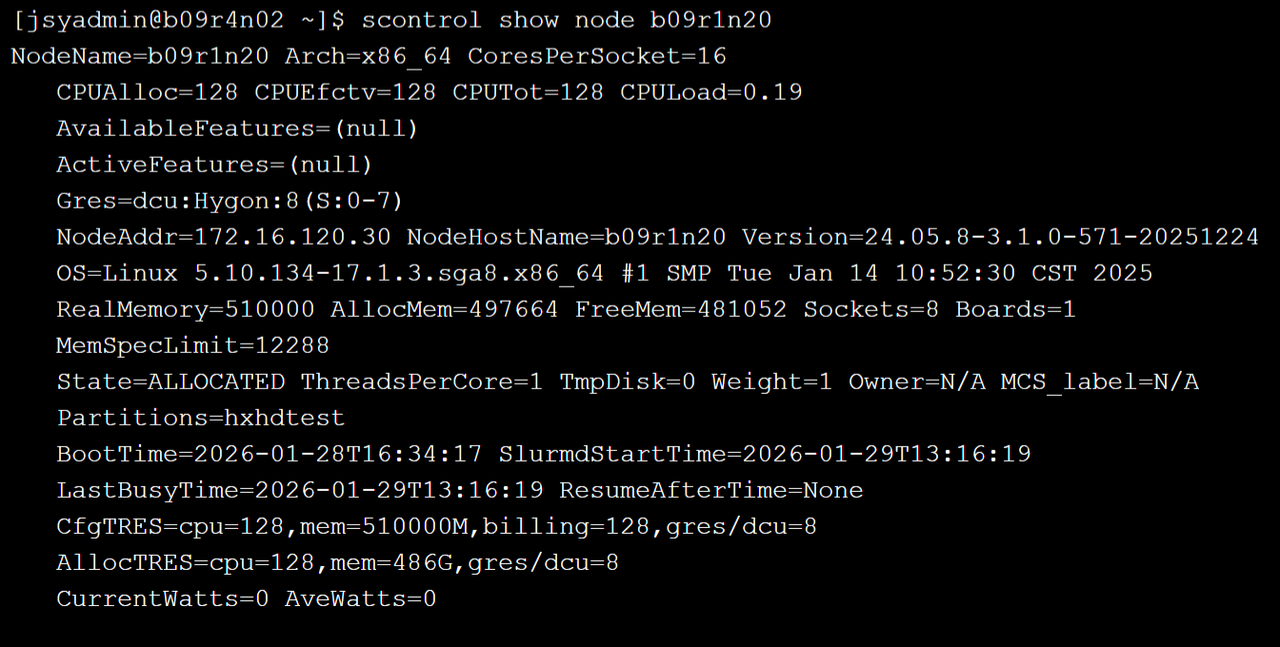 输出信息包含节点名称(NodeName)、架构(Arch)、每个 socket 的核心数(CoresPerSocket)、总 CPU 数量(CPU Tot)、节点当前状态(State)等详细信息,这些信息有助于了解节点的可用资源、性能和当前运行状态。
输出信息包含节点名称(NodeName)、架构(Arch)、每个 socket 的核心数(CoresPerSocket)、总 CPU 数量(CPU Tot)、节点当前状态(State)等详细信息,这些信息有助于了解节点的可用资源、性能和当前运行状态。
使用 scontrol 查看作业详细信息,示例如下: 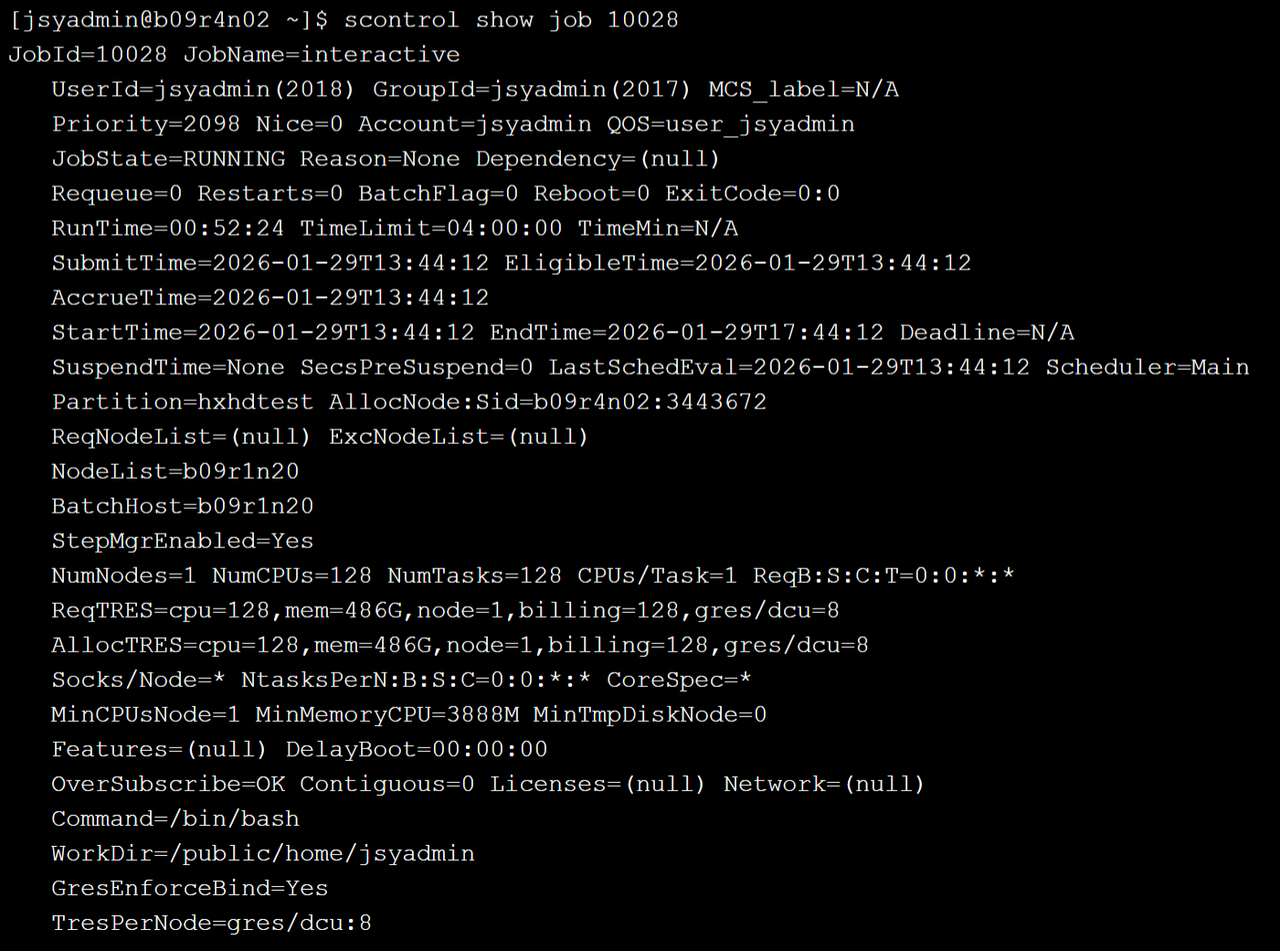 输出该作业的详细信息,包含作业名称(JobName)、提交者(UserId)、当前状态(JobState)、提交(SubmitTime)、开始(StartTime)、结束(EndTime)时间,提交命令(Command)、作业路径(WorkDir)等。这些信息有助于用户了解作业的运行情况和资源使用情况。
输出该作业的详细信息,包含作业名称(JobName)、提交者(UserId)、当前状态(JobState)、提交(SubmitTime)、开始(StartTime)、结束(EndTime)时间,提交命令(Command)、作业路径(WorkDir)等。这些信息有助于用户了解作业的运行情况和资源使用情况。
批处理作业采用脚本方式提交。基本格式如下:
sbatch xxx.sh其中,xxx.sh 为 sbatch 脚本。脚本中作业控制指令以“#SBATCH”开头,其余格式与 shell 脚本相同。以下作业脚本为例:
#!/bin/bash
#SBATCH -J TEST #作业名称
#SBATCH -p onesitelarge #队列名称
#SBATCH -N 2 #需要几个节点
#SBATCH --ntasks-per-node=8 #单节点多少个rank
#SBATCH --cpus-per-task=16 #每个rank 需要多少个cpu核
#SBATCH --gres=dcu:8 #单节点多少张卡
#SBATCH -o %j #标准输出文件名
#SBATCH -e %j #标准错误输出的文件名
mpirun ./xxx #作业运行命令SBATCH 作业控制指令说明:
| -J | 作业名称,使用 squeue 看到的作业名 |
| -n | 作业申请的 cpu 核心数 |
| -N | 作业申请的节点数 |
| -p | 指定作业提交的队列 |
| -t | "指定作业的执行时间,若超过该时间,作业将会被杀死" |
| -o | "指定作业标准输出文件的名称,不能使用shell环境变量" |
| -e | "指定作业标准错误输出文件的名称,不能使用 shell 环境变量" |
| -w | 指定分配特定的计算节点 |
| -x | 指定不分配特定的阶段节点 |
| --exclusive | 指定作业独占计算节点 |
| --mem | 指定作业在每个节点使用的内存限制 |
| --mem-per-cpu | 限定每个进程占用的内存数 |
| --dependency | 限定作业依赖关系 |
| --gres | "指定作业需要的通用资源(如 GPU)。例如 gpu:1 表示请求 1 个 GPU" |
此外,SLURM 提供一系列环境变量用于动态地获取作业运行时的信息,从 而更灵活地控制和配置作业运行环境。
SLURM 常见环境变量说明:
| SLURM_JOBID | 当前作业 ID |
| SLURM_JOB_NODELIST | 当前作业使用的节点列表 |
| SLURM_NTASKS_PER_NODE | 每个节点上分配的任务数 |
| SLURM_JOB_NAME | 当前作业名称 |
| SLURM_SUBMIT_DIR | 作业提交的目录 |
| SLURM_JOB_CPUS_PER_NODE | 当前作业每个节点使用的核心数 |
作业提交脚本中,可以使用以上环境变量动态地获取作业信息和资源配置, 例如:
#!/bin/bash
#SBATCH -J TEST #作业名称
#SBATCH -p onesitelarge #队列名称
#SBATCH -N 2 #需要几个节点
#SBATCH --ntasks-per-node=8 #单节点多少个rank
#SBATCH --cpus-per-task=16 #每个rank 需要多少个cpu核
#SBATCH --gres=dcu:8 #单节点多少张卡
echo "Job ID: $SLURM_JOB_ID"
echo "Job Name: $SLURM_JOB_NAME"
echo "Nodes Allocated: $SLURM_JOB_NODELIST"
echo "Number of Tasks: $SLURM_NTASKS"
echo "CPUs per Task: $SLURM_JOB_CPUS_PER_NODE"
echo "Submit Directory: $SLURM_SUBMIT_DIR"该命令用于查看作业的详细信息,如作业状态、资源使用情况、执行时间以 及退出状态等。用户可以通过不同的选项筛选和格式化输出,以获取特定时间范 围内的作业记录,便于进行性能分析和资源管理。
sacct 命令常见选项说明:
| --help | 查看 sacct 命令帮助信息 |
| -j | 查看指定作业的记录 |
| -S | 指定开始时间,如: -S 2024-04-01 |
| -E | 指定结束时间,如:-E 2024-04-02 |
| -o | 指定输出格式,如:-o JobID, JobName, State, Elapsed |
| -a | 显示所有作业信息,包括已完成的作业 |
sacct 示例如下:
a. --format 指定显示的字段,如作业 ID、用户、分配的 CPU 数量、耗时和 状态等。  b. 按时间范围筛选作业
b. 按时间范围筛选作业 
该命令用于取消已经提交的作业,非 root 用户只能取消本账户的作业。
scancel 命令常见选项说明:
| --help | 查看 scancel 命令帮助信息 |
| -u | 取消指定用户的所有作业 |
| -n | 取消指定名称的作业,支持通配符匹配多个作业 |
| -p | 取消指定分区的所有作业 |
| -t | 取消指定状态的作业 |
如取消作业号为47433887的作业,用法示例: 