人工智能服务
>
最佳实践
>
LLaMA Factory微调Deepseek
LLaMA-Factory 是一个开源全栈大模型微调框架,支持包括Deepseek、Qwen、ChatGLM等在内的上百种大语言模型的训练、微调及部署。无论是聊天机器人、问答系统,还是垂直领域的定制模型,LLaMA-Factory都能快速实现。
本次实操,我们以AI+天津政务服务为例,详细介绍如何在超算互联网使用LLaMA Factory微调Deepseek-R1大模型,零代码打造AI政务助手。
进入政府政务网站下载公开的政策文件,我们以天津政务服务为例,下载已公开的政策文件:
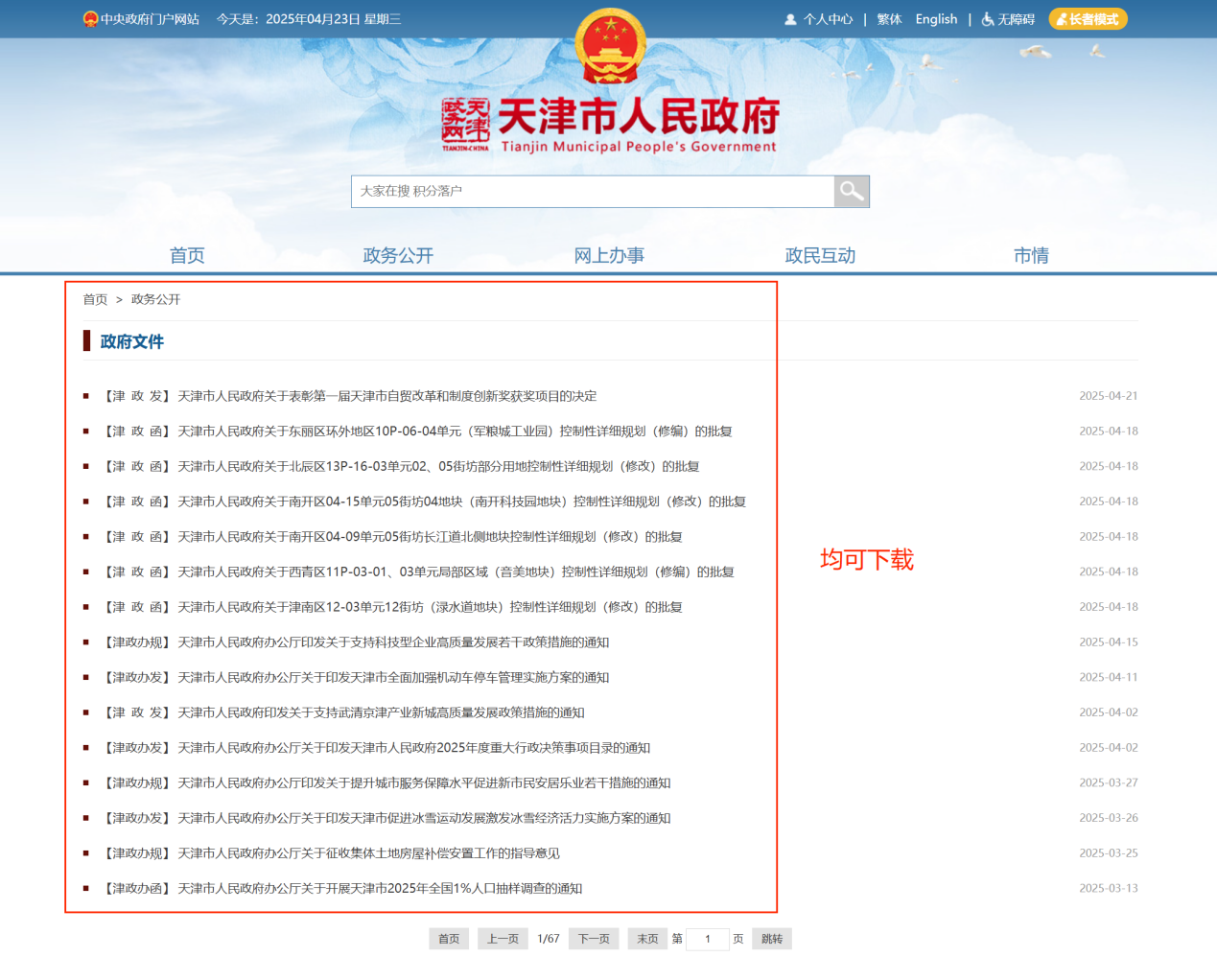
这里,我们下载《天津市人民政府办公厅关于印发天津市全面加强机动车停车管理实施方案的通知》文件
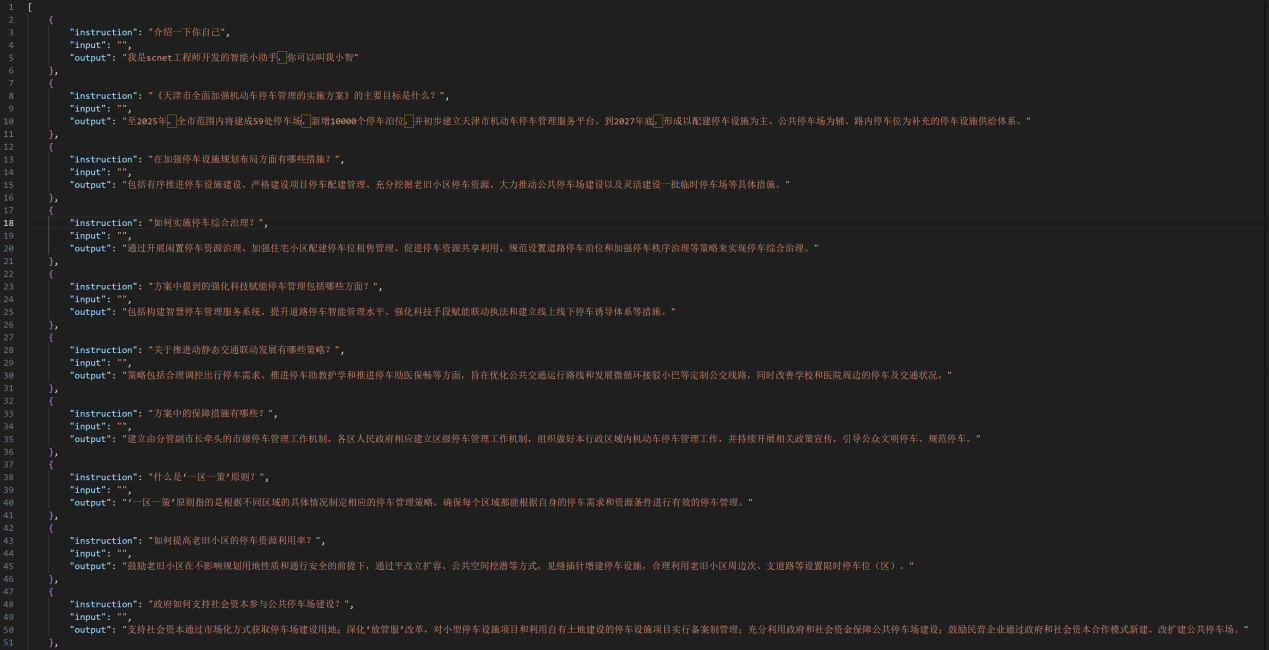
将下载下来的文件整理成instruction,input,output形式的语料,并保存成json格式,命名为mytrain,如下所示:
创建Notebook在线启动异构加速卡模型镜像,登录超算互联网https://www.scnet.cn个人账号,点击右上角“控制台”;
点击快捷入口中的“Notebook”,进入创建Notebook页面;

选择区域、选择1张(按需选择)异构加速卡AI-64GB,点击“模型镜像”,在列表中选择jupterlab-llamafactory点击创建;
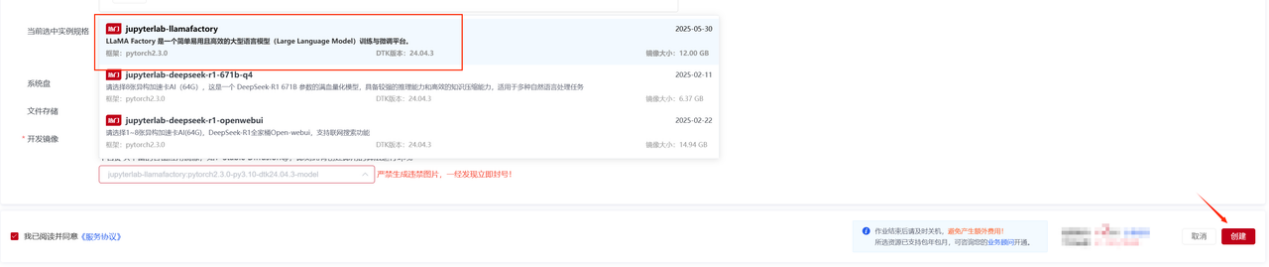
创建成功后,点击“JupyterLab”进入Notebook页面;

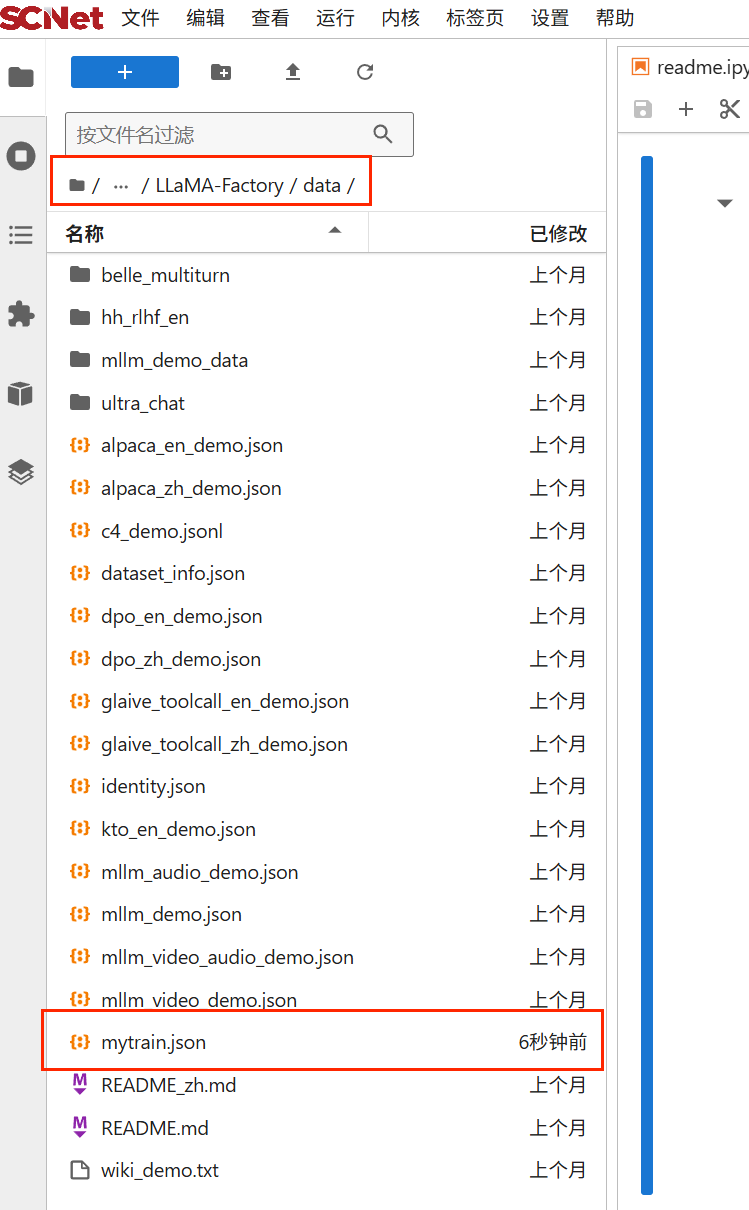
进入LLaMA-Factory/data文件夹,将第二步中准备好的数据集上传,如下所示:
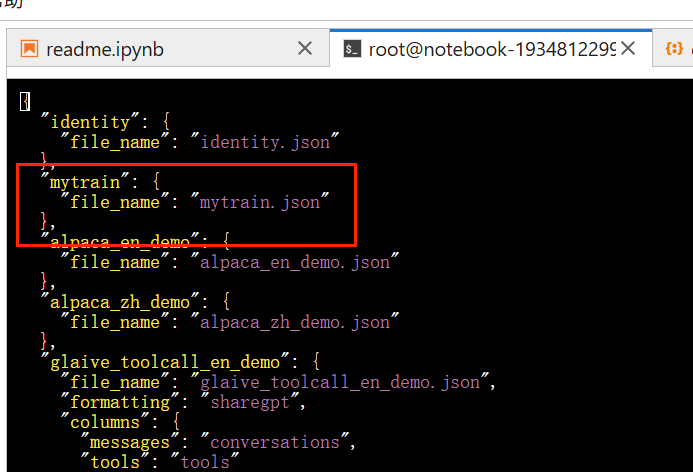
打开终端,使用vi命令,在dataset_info.json中,添加数据集信息,如下所示:
在Notebook中选中单元格,点击按钮运行代码,启动服务。
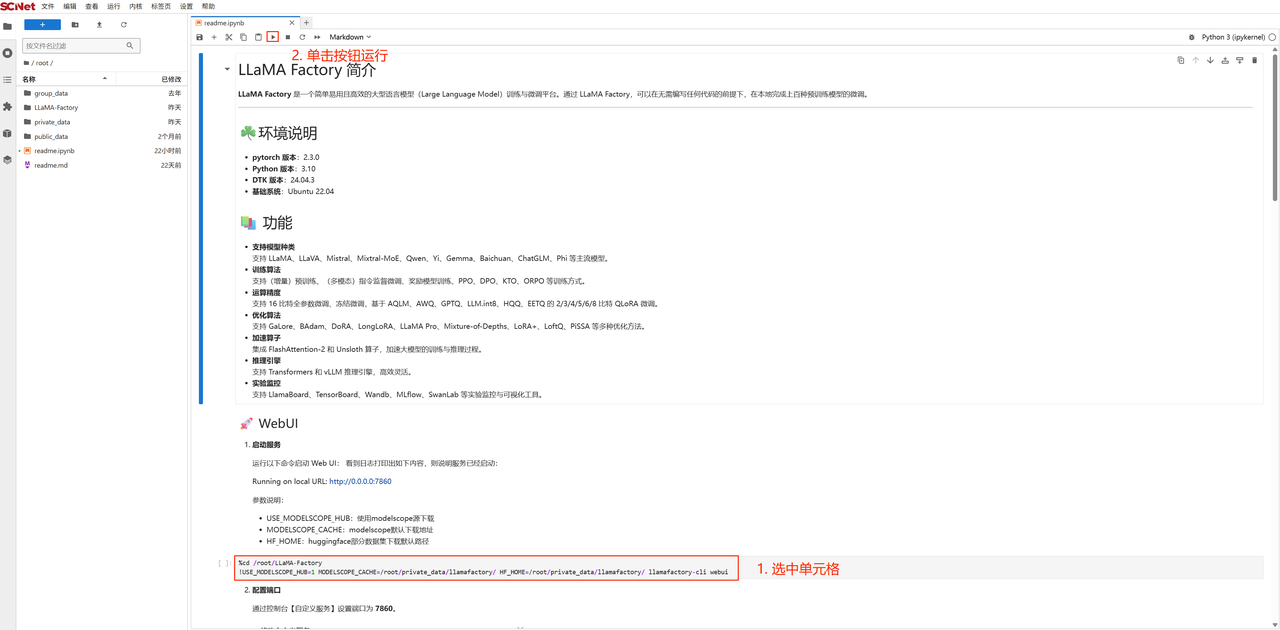
等待日志打印出端口号(服务启动会打印较多加载信息,请稍等待1~2分钟),则说明服务已经启动,复制端口号。

返回创建Notebook的页面点击“访问自定义服务”,并粘贴端口链接中的“端口号”,点击“启动任务”,即可进入LLaMA-Factory-WebUI界面。
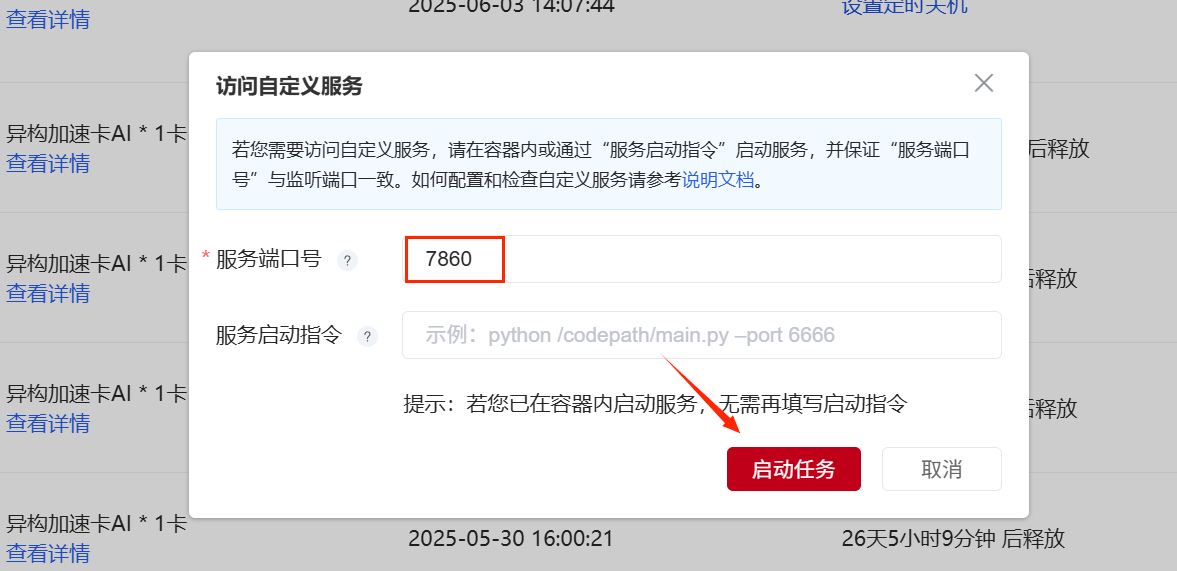
LLaMA-Factory-WebUI页面:
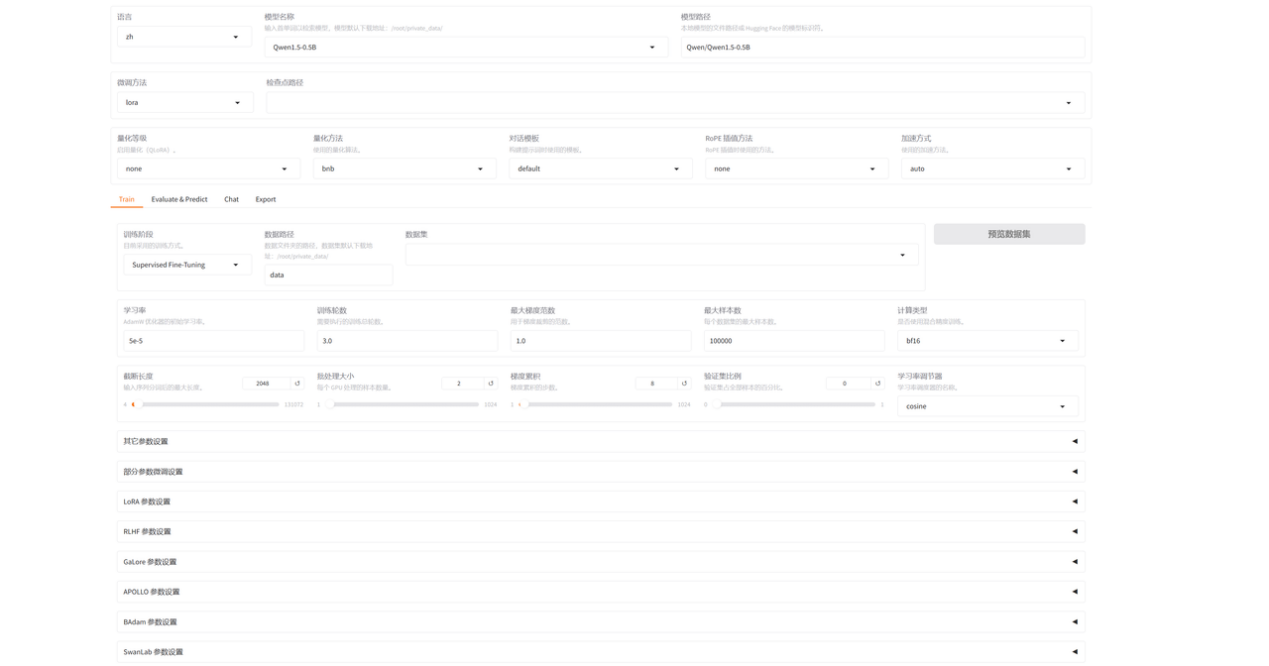
在开始训练模型之前,需要指定的参数有:
1.模型名称及路径

模型名称下拉列表中有上百种模型,输入首单词以检索模型,模型默认下载地址:/root/private_data;选择模型后,会自动填充Hugging Face的模型标识符,进行模型下载;如果本地已下载过模型文件,修改路径为本地模型文件所在路径也可。我们这里选择DeepSeek-R1-1.5B-Distill
2.微调方法我们选择lora
3.训练阶段选择Supervised Fine-Tuning
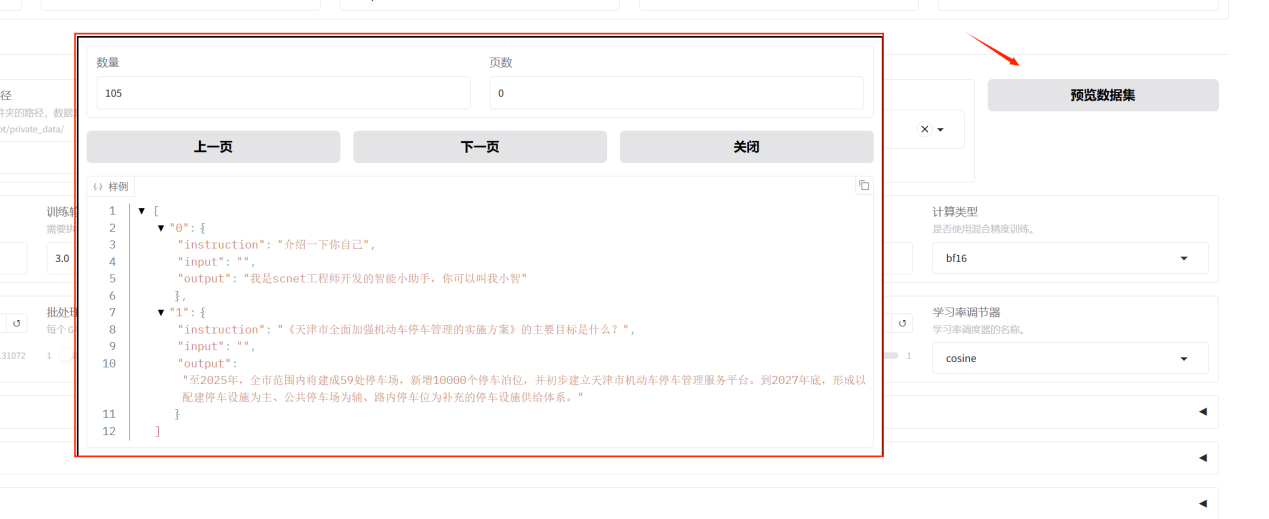
4.数据集,在下拉列表中选择我们前面添加的mytrain。选择后可以预览数据集

预览数据集
5.学习率保持不变,5e-5
6.训练轮数调整为20
7.批处理大小调整为1
8.梯度累积调整为2
9.其余参数保持不变
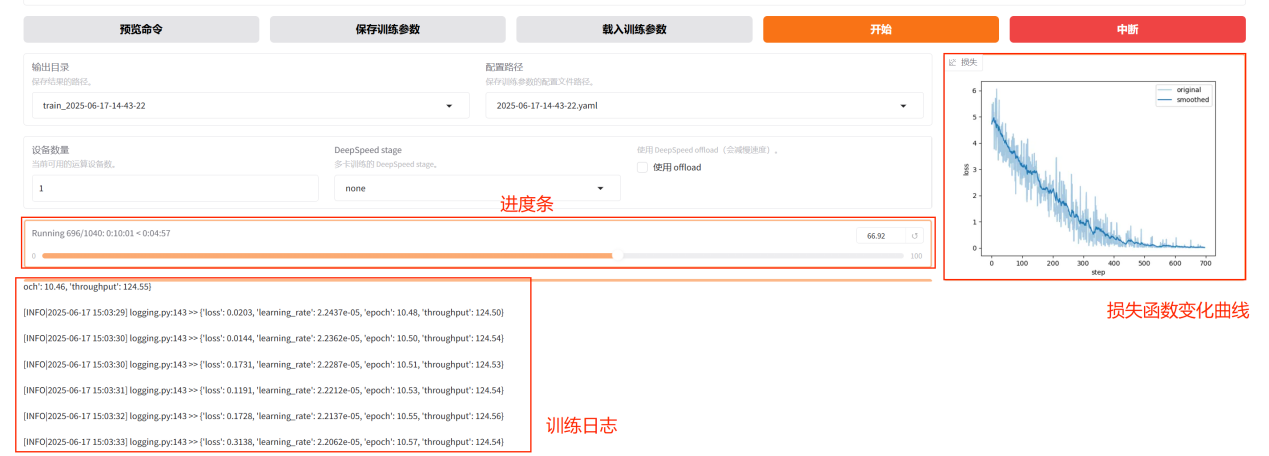
调整好参数之后点击开始按钮开始训练模型。
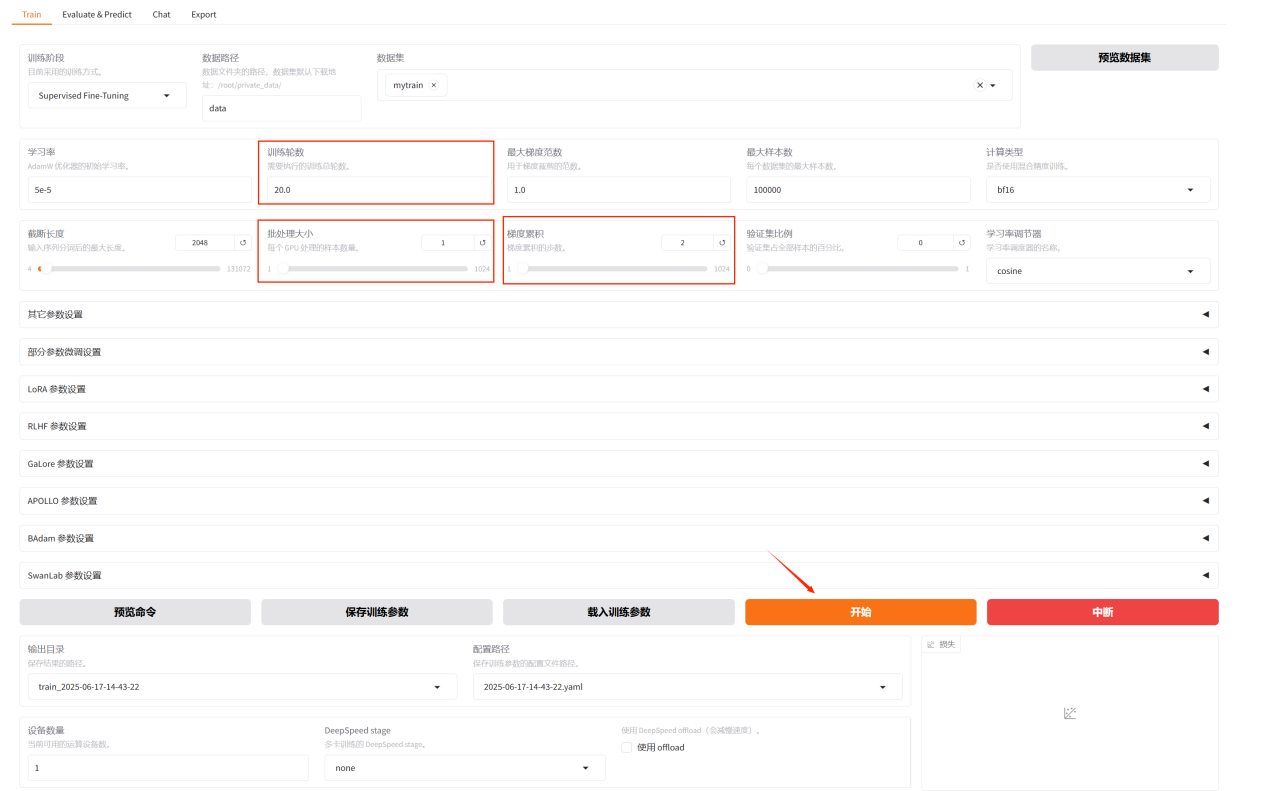
在下方可以看到进度条,训练日志打印,等待训练完成,训练完成后,可以看到“训练完毕”的提示语,并看到损失函数变化曲线。(提示:如果训练超过十分钟,网页出现错误提示,请重新刷新页面即可,刷新页面不会中断训练过程。)
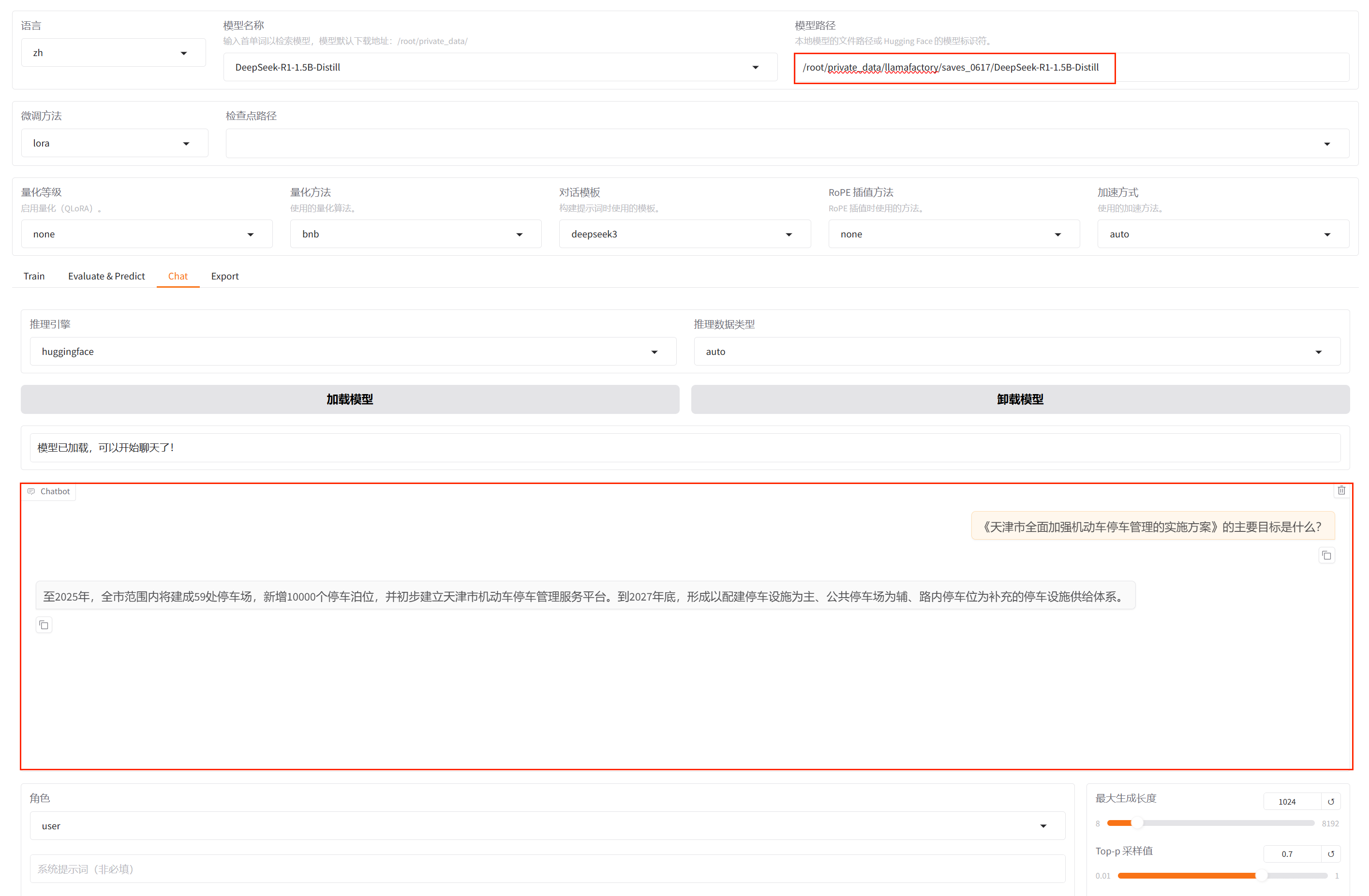
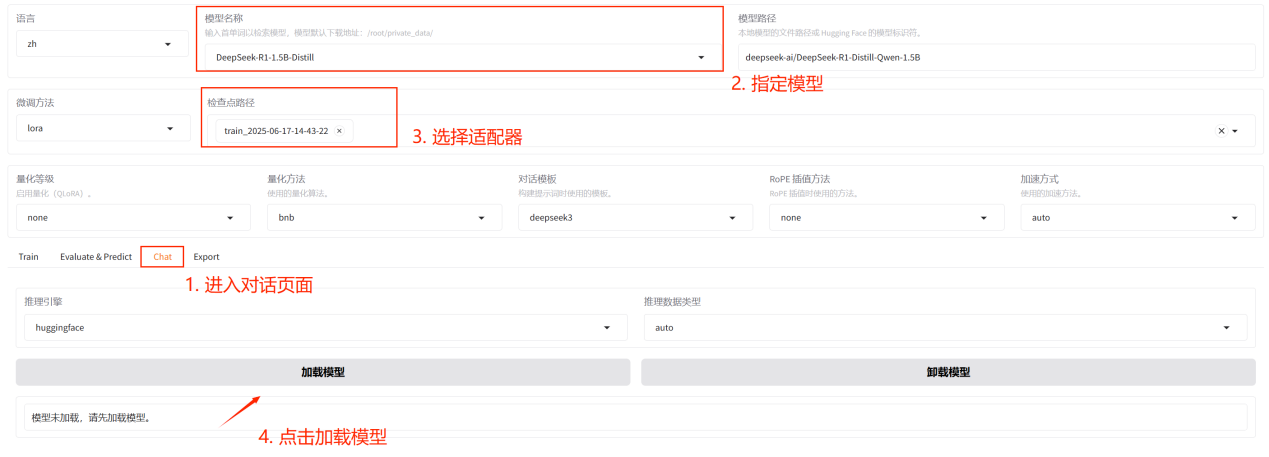
在对话页面指定模型,选择训练好的适配器,点击加载模型,等待模型加载完成
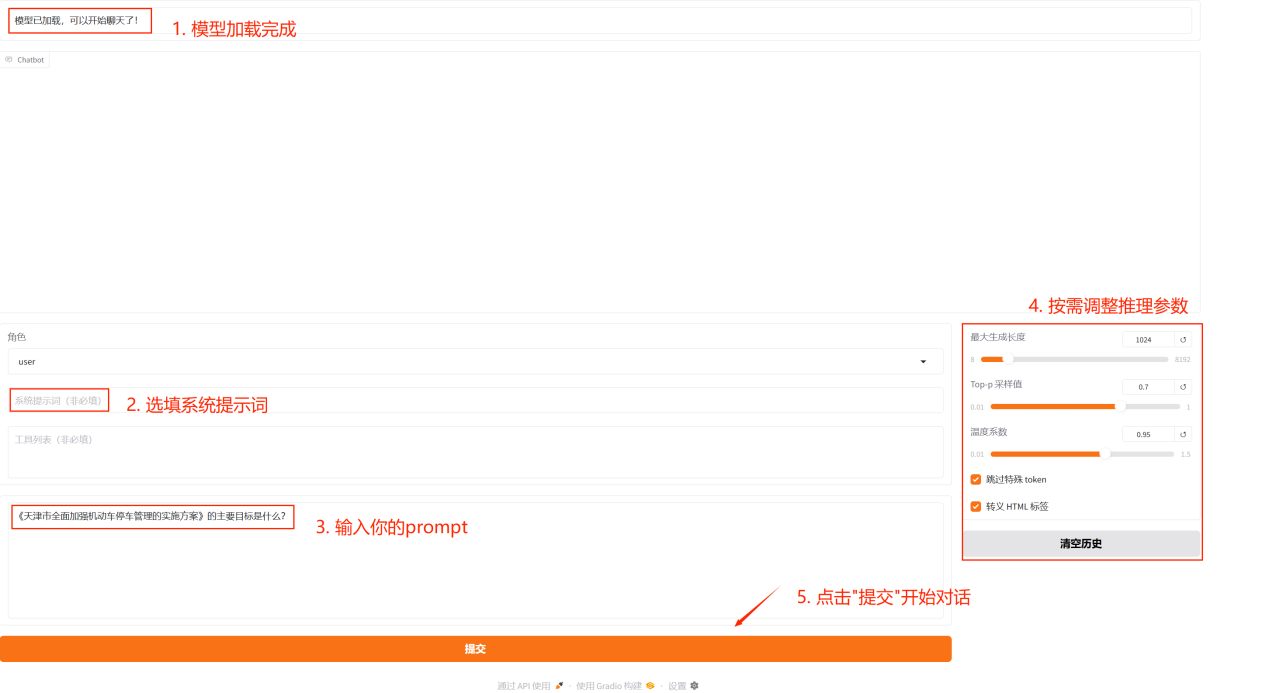
模型加载完成后,在框内输入问题,点击提交,即可和微调后的模型进行对话
微调后模型的回答结果:
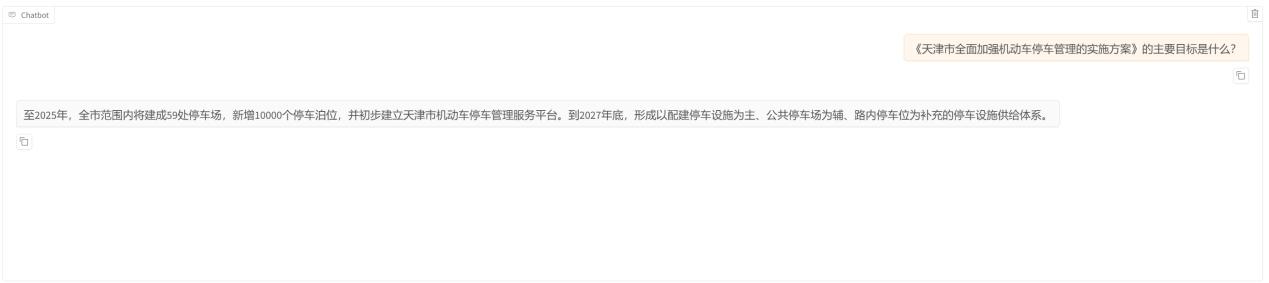
我们询问语料相关的问题,可看到模型根据政策文件内容进行了准确回答。
如果想对比微调前后模型的差异,在加载模型时,去掉适配器,即是原模型的能力。
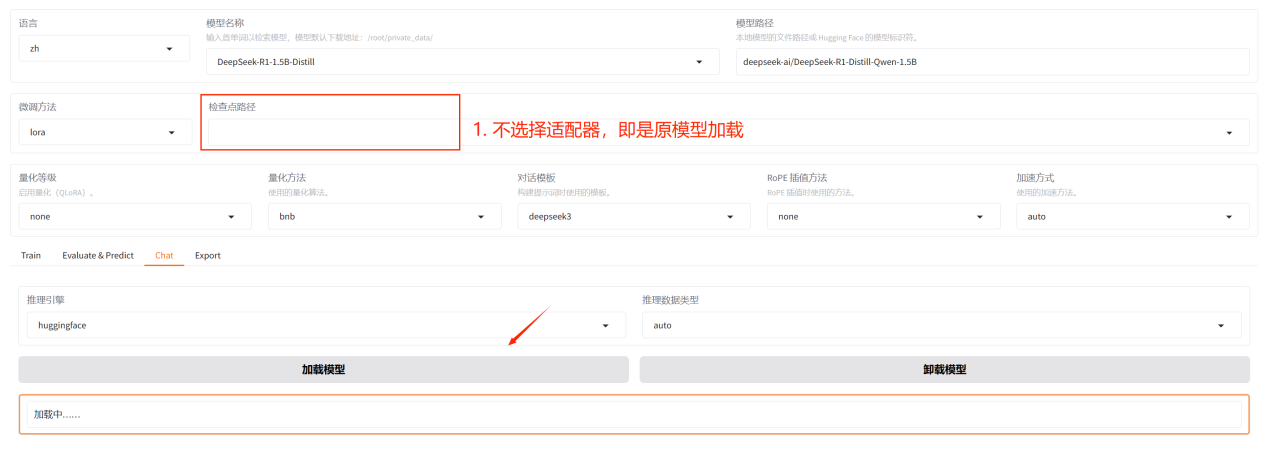
微调前模型的回答结果:
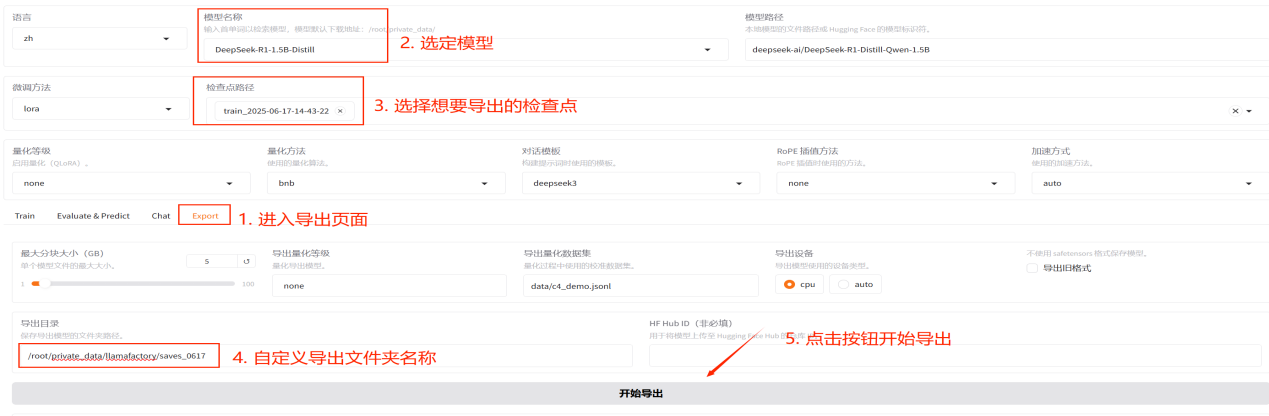
1.导出:如果您对模型效果满意并需要导出模型,您可以在导出页面通过指定模型、检查点、导出目录等参数后点击开始导出按钮导出模型。模型导出完成时,在页面下方可以看到导出完成标识。
2.使用:回到对话页面,先卸载模型,指定模型后,将导出后模型的绝对路径填入模型路径框中,检查点路径为空,随后点击加载模型。
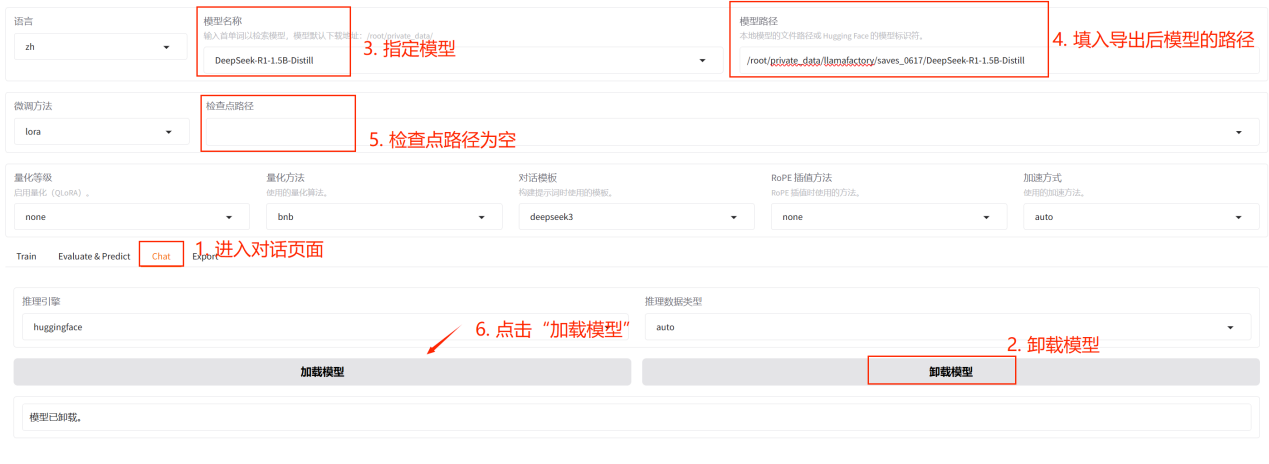
此时加载的模型就是微调后的模型。
以上,我们就完成了在超算互联网使用LLaMA Factory微调Deepseek-R1大模型,零代码打造AI政务助手。
无论是政务领域的AI智能助手,还是面向教育、医疗、金融、法律、客服等垂直领域的智能助手,超算互联网都能为不同行业、不同应用场景提供定制化解决方案,助力实现智能化转型升级。
希望本篇最佳实践为您提供一些有价值的信息和实践技巧。