
新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算AI快讯、前沿应用、学术研究等。
本期超算&AI应用周报共5969字,预计阅读时间21分钟,您可以重点专注以下内容。
超算AI快讯:
AI模型:Google开源视觉语言模型PaliGemma、Huggingface多模态模型Idefcs2、英伟达Llama3-ChatQA-1.5模型、国产MiniCPM-Llama3-V 2.5上线超算互联网;
HPC软件:CP2K 2024.1版本、LAMMPS 7Feb2024版本上线超算互联网;
前沿应用:微软重塑生产版图:Copilot解锁个性化AI助手,AI PC无缝融合PyTorch;Meta「变色龙」模型登场,340亿参数重塑多模态AI版图;王小川又做搜索!百川智能Baichuan 4助手发布
学术研究:普林斯顿Meta携手打造150B Token全可微MoE架构Lory;Slicedit:一键换主体,冲浪者秒变钢铁侠;加州大学团队打造POLYGON,多靶点抗癌药物设计准确率高达82.5%
一、超算AI快讯:
超算互联网上线Google开源视觉语言模型PaliGemma
本周,超算互联网上线Google开源视觉语言模型PaliGemma,包括3B大小的预训练 (PT) 模型和混合模型,这些模型分辨率各异,提供多种精度以便使用,支持一键启用notebook运行推理。
PaliGemma的应用场景广泛,结合图像处理和语言理解能力,支持多种视觉语言任务,包括图像描述、问答、目标检测、目标分割等。
图像标题生成:当被提示时,PaliGemma 能够为图像生成标题。
视觉问题问答:PaliGemma 可以回答关于图像内容的问题,只需将你的问题连同图像一起传入即可。
目标检测:PaliGemma 可以识别图像中的目标物体,并给出相应的坐标信息,例如“图片中有一只猫,坐标为 (100, 100, 200, 200)”。
目标分割:PaliGemma 可以对图像中的目标物体进行分割,生成相应的分割掩码。

超算互联网上线多模态模型Idefcs2,文字、图片、音频、视频全搞定
来自Huggingface的多模态团队HuggingfaceM4发布了最新的多模态模型Idefcs2,接受任意文本序列和图像序列作为输入,并据此生成文本。它可用于回答图像相关的问题、描述视觉内容、基于多幅图像创作故事、从文档中提取信息以及执行基本的算术运算。
超算互联网已上线Idefcs2-8b、Idefcs2-8b-chatty、Idefcs2-8b-base版本,支持开发者一键启用notebook进行细分任务微调。
从技术细节来看,Idefics2在多个方面实现了创新:
图像处理:Idefics2摒弃了传统的固定尺寸图像裁剪方式,而是保持图像的原生分辨率和纵横比,通过子图像切分等策略来适应输入要求。这不仅可以更好地保留视觉信息,也提高了处理效率。
OCR性能:通过针对性的训练数据,Idefics2的光学字符识别能力得到了大幅提升,可以准确转录图像或文档中的文字内容,从而更好地理解图表和文档等结构化信息。
模型架构:相比上代,Idefics2在融合视觉特征到语言主干网络的方式上进行了优化,采用了Perceiver池化和MLP模态映射的方式,进一步简化了跨模态信息的交互。

国产MiniCPM-Llama3-V 2.5上线超算互联网,GitHub 星标 2.8k+
日前,面壁智能和清华大学自然语言处理实验室联合研发的小钢炮端侧模型 MiniCPM 系列上新,带来多模态模型 MiniCPM-Llama3-V 2.5。
MiniCPM-Llama3-V 2.5 发布后火速登顶 HuggingFace 和 GiHub Trending榜双榜首,与 Meta、微软、谷歌等科技巨头共同从全球 66 万模型中脱颖而出。
超算互联网已上线MiniCPM-Llama3-V 2.5,模型核心亮点包括:
OCR 能力 SOTA:高清图像高效编码技术,可以高效编码及无损识别 180 万高清像素图片,并且支持任意长宽比,包括 1:9 极限比例,突破了传统技术仅能识别 20 万像素小图的瓶颈;
高效部署:量化后仅 8G显存,4070 显卡轻松推理,并可在手机端以 6-8tokens/s 速度高效运行;
图像编码速度大幅提升:首次整合 NPU 和 CPU 加速框架,并结合显存管理、编译优化技术,在 MiniCPM-Llama3-V 2.5 图像编码方面实现了 150 倍加速提升;
支持 30+ 多种语言:利用自研的跨语言泛化技术,仅需少量翻译数据即可实现多语言多模态对话的高效泛化。

英伟达Llama3-ChatQA-1.5模型上线超算互联网,提升对话问答和表格推理能力
英伟达发布Llama3-ChatQA-1.5,该模型在问答(QA)和检索增强生成(RAG)方面表现出色,8B和70B两款模型版本已在超算互联网发布,其中70B模型在各项评估基准上,基本都超过了Llama-3-instruct-70B和Command-R-Plus。
Llama3-ChatQA-1.5的创新点主要体现在以下几个方面:
融合会话问答和表格推理能力:该模型不仅擅长处理开放域的对话式问答,在理解和推理包含表格数据的复杂问题上也有出色表现。
依靠高质量数据训练,无需借助ChatGPT合成数据:Llama3-ChatQA-1.5的训练数据主要来自人工标注的会话式问答数据集以及其他高质量QA数据,并未使用ChatGPT等模型生成的合成数据。
检索增强能力强劲:通过对单轮检索模型的精细调优,Llama3-ChatQA-1.5能够高效利用检索结果,在需要检索的场景下也能保持出色的性能。
Llama3-ChatQA-1.5应用广泛,开发者可以在超算互联网利用该模型实现智能客服系统、教育辅导、信息检索与过滤、创意写作辅助、多语言翻译与交流、个性化推荐系统等关键功能和应用,提高信息处理的效率和准确性。

CP2K 2024.1版本上线超算互联网
CP2K是一个开源的量子化学和固态物理软件包,用于对固态、液态、分子、周期性、材料、晶体和生物系统进行原子模拟。它提供了不同的建模方法,如基于密度泛函理论(DFT)的结构优化、分子动力学模拟等。
CP2K 2024.1版本已在超算互联网上线,主要更新内容包括:
新特性:包括Sphinx基础的手册发布、TDDFPT的多项改进、RI-HFX的K点支持(含梯度和ADMM)、ADMM输入简化、长程量子计算(WF)在短程DFT嵌入中的应用等。
新库支持:实验性支持DLA-Future特征值求解器,以及使用ECPs libgrpp库进行计算。
重大变更:移除了SINGLE_PRECISION_MATRICES关键字,默认在SCF收敛失败时终止运行,不再支持NDEBUG,生产用Docker文件移至新仓库等。
修复:正了LnPP2基组中的一些错误,修复了使用LOW SPIN ROKS时Wannier定位问题,修复了CIF文件中原子位点解析问题等。

LAMMPS 7Feb2024版本上线超算互联网,增加新计算命令
LAMMPS是一款广泛应用于材料科学、化学、生物物理等领域的高性能分子动力学模拟软件。它特别擅长于执行大规模并行计算,LAMMPS 7Feb2024版本已在超算互联网上线,主要更新内容包括:
新计算命令:添加了新的 compute pace 命令,用于评估 ACE 描述符,类似于 compute snap。
变量功能:新增了变量的 “ternary()” 函数。
新的计算和修正命令:引入了用于识别欠协调粒子的新计算命令和测量粒子非仿射位移的新修正命令。
ReaxFF/原子计算:新增了 compute reaxff/atom 计算,以获取 ReaxFF 的局部键合信息。
FFT库支持:添加了对 heFFTe 库进行 FFTs 的支持。
向后兼容性说明:移除了 “reax/c” 别名,现在必须使用 “reaxff”。二进制重启文件的格式发生了变化,不再支持使用 lepton 键合风格或角度风格的情况。

二、前沿应用:
微软重塑生产版图:Copilot解锁个性化AI助手,AI PC无缝融合PyTorch
5 月 22 日凌晨,微软在Build开发者大会上重点发布了关于AI技术及其带来的新工具。CEO萨蒂亚·纳德拉强调了微软长期以来的梦想,即让计算机更好地理解人类并帮助人们高效地处理信息。
本次微软Build开发者大会亮点如下:
Copilot+PC:新一代PC形态,首批产品将搭载高通Snapdragon X系列处理器,后续将推出基于英特尔和AMD处理器的版本。这些设备因内置NPU具备强大AI算力,能显著提升AI任务处理能力。Windows Copilot Runtime通过API和端侧模型(如Phi-Silica SLM)为Windows带来智能搜索、翻译等AI功能,并优化了资源使用效率。
AI开发工具与框架:DirectML作为Windows上的机器学习高性能API,支持多种硬件和AI框架集成,如ONNX Runtime、PyTorch和WebNN,使得开发者能更便捷地在Windows上部署模型。同时,Windows Subsystem for Linux (WSL)促进了跨平台的AI开发。
办公效率工具革新:微软发布了“Recall”功能,可搜索电脑上的一切,极大地提高办公效率;实时字幕翻译支持40多种语言;Paint应用新增了Cocreator图像生成AI功能,以及Restyle Image功能,让用户在图片编辑上有更多创意空间。
Phi-3模型家族:微软推出了新的多模态小语言模型Phi-3-Vision,具有4.2B参数,能在Azure上使用。它结合文本和图像处理能力,支持图表理解和视觉推理,表现超越了部分更大规模的模型。这些模型遵循微软的AI责任和安全标准,并对开发者开源。
奥特曼预告新模型:OpenAI CEO奥特曼出席活动,表示GPT-4o将更快且成本更低,并预告下一个大模型的到来。他强调未来模型将更智能,但提醒开发者仍需努力将技术转化为实际应用价值。(机器之心)
内容链接:https://www.jiqizhixin.com/articles/2024-05-22-4
Meta「变色龙」模型登场,340亿参数重塑多模态AI版图
Meta公司近期发布了一项名为Chameleon(变色龙)的新型混合模态基座模型,该模型针对多模态处理进行了革新,尤其在文本与图像的融合方面展现出显著能力。其核心特点包括:
统一的Transformer架构:Chameleon采用了与GPT-4o类似的端到端训练方法,但不仅仅局限于文本,而是整合了文本、图像和代码的混合模态训练,利用统一的Transformer架构处理所有输入和输出。
早期融合的多模态处理:通过将不同模态的信息在训练初期就进行混合(包括将图像离散化为token),所有模态的数据被映射到一个共同的表示空间,使模型能够无缝地理解并生成包含文本和图像交错的多模态内容。
技术创新应对挑战:为了解决多模态融合带来的优化稳定性和模型扩展性难题,Chameleon引入了一系列架构创新,如QK归一化、注意力层和前馈层后的dropout,以及Zloss正则化,以保证训练的高效与稳定性。
强大的分词器系统:为实现模态的token化,Chameleon开发了专门的图像分词器,能够将图像编码为token,同时也基于sentencepiece库训练了包含文本和图像token的混合分词器,确保了模态间信息的高效转换和处理。

广泛预训练数据:使用了多样化的预训练数据集,包括纯文本、文本-图像对以及多模态文档,且强调使用的是公开数据源,没有涉及Meta内部产品数据,以确保模型的通用性和公正性。
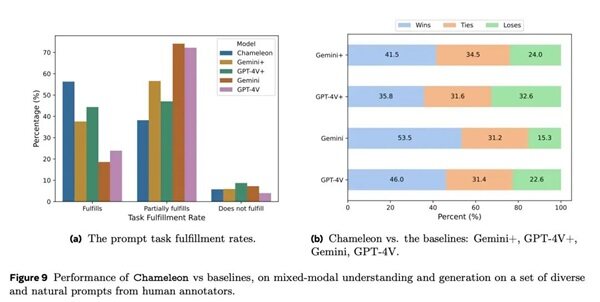
性能优越:在多项基准测试中,Chameleon显示出卓越的性能,尤其是在视觉问答和图像标注任务上,刷新了最先进水平(SOTA),在纯文本任务上也与顶尖模型如Gemini Pro和Mistral系列相当。(新智元)
内容链接:https://hub.baai.ac.cn/view/37266
王小川又做搜索!百川智能Baichuan 4助手发布
5月22日,百川智能发布了新一代大模型Baichuan 4,该模型在通用能力、数学及代码能力上均有显著提升,超越了前代产品。同时,公司还推出了首个AI助手“百小应”,该助手基于Baichuan 4备定向搜索与多轮搜索功能,能提供更针对性的答案并优化用户体验。

Baichuan 4的核心主要包括:
技术创新与性能提升:相较于Baichuan 3,Baichuan 4在通用能力上提升了超过10%,数学和代码能力分别提升了14%和9%。这表明模型在处理广泛任务类型、数学计算和编程相关问题上有了显著的进步。
多模态能力:Baichuan 4的多模态能力接近GPT-4V,在MMMU、MMBench-EN、CMMMU、MMBench-CN、MathVista等多个评测基准上表现优异,特别是在知识百科、长文本、生成创作等文科类中文任务上展现出卓越的表现。
数据与模型创新:在数据处理上,百川智能利用合成数据扩充了训练集,提高了数据质量和数量。模型训练上,从经验科学转向数学化,通过大量实验将调参过程从玄学化转变为科学化,减少了调参的随机性,并在长窗口尺寸上进行细致优化,找寻最佳参数配置。
强化学习与安全性:通过强化学习策略,Baichuan 4致力于提升真实、无害、有用的3H(真实HyPERION, 无害Harmless, 有用Helpful)阶段训练,以及融合人类反馈(RLHF)和机器反馈(RLAIF),增强模型指令遵循能力,确保模型安全可控。(智东西)
内容链接:https://mp.weixin.qq.com/s/Tr-ZzJfMAzRRpirYxTKSaQ
三、学术研究:
普林斯顿Meta携手打造150B Token全可微MoE架构Lory
近期,普林斯顿大学联合Meta在arXiv上发表了他们最新的研究成果——Lory模型,该模型标志着首个全可微混合专家(MoE)架构在语言模型预训练领域的突破。Lory名称灵感来源于一种拥有彩虹般羽毛的鹦鹉,象征其在“软MoE”设计上的独到之处。

Lory模型的核心要点主要包括两个重要技术创新:
因果分段路由策略:Lory模型摒弃了传统MoE模型中基于单个token的路由方式,转而采用因果分段路由策略。这种新策略不再单独为每个token决定路由,而是对整个语句段进行专家合并。这样做不仅保持了语言模型的自回归属性,还提升了路由效率。
基于相似性的数据批处理方法:针对预训练语言模型通常随机拼接文本片段可能导致专家模型泛化能力不足的问题,Lory借鉴了ICLR 2024中的一项技术,通过将相似的文档序列化地连接起来构造训练样本。这种做法使得专家模型能更专注于特定领域或主题,促进模型的专业化,提高学习效率。实验证明,相比随机批处理,基于相似度的批处理策略能带来更大的损失减少,进一步优化模型性能。
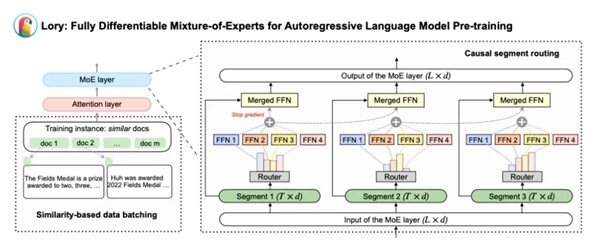
这两个关键技术点共同作用下,Lory模型不仅在训练效率上显著优于传统稠密模型,还在多种自然语言处理任务上展现了优异的性能,如常识推理、阅读理解、闭卷问答和文本分类,显示出随着专家数量增加模型表现持续优化的趋势。
论文链接:https://arxiv.org/abs/2405.03133
Slicedit:一键换主体,冲浪者秒变钢铁侠
近日,巴黎矿业大学和以色列理工学院的研究团队携手发布了一项名为Slicedit的革新性视频编辑模型。该模型融合了文本到图像的扩散模型及针对视频时空切片的预处理技术,无需改动视频背景,即可实现对视频中主体对象的变换。

该模型技术亮点包括:
空间时间切片:从视频三维空间抽取二维片段,确保动态对象调整同时保留背景完整。
扩展注意力机制:增强传统注意力模型处理时间序列数据能力,通过考虑相邻帧信息捕捉动态。
DDPM反演:应用反向去噪过程,基于用户编辑要求,将视频帧转化为噪声向量并通过去噪重构原始数据
论文链接:https://arxiv.org/abs/2405.12211
加州大学团队打造POLYGON,多靶点抗癌药物设计准确率高达82.5%
近日,加州大学圣地亚哥分校的研究团队研发了一种基于生成人工智能和强化学习的深度机器学习模型---POLYGON。它能够模拟并加速药物发现初期耗时的化学过程,尤其擅长设计能同时作用于多个蛋白质靶标的药物分子。此模型通过嵌入化学空间并迭代采样,生成了具有预期抑制两个特定蛋白质靶标活性、良好的药物相似性和易于合成特性的新分子结构。
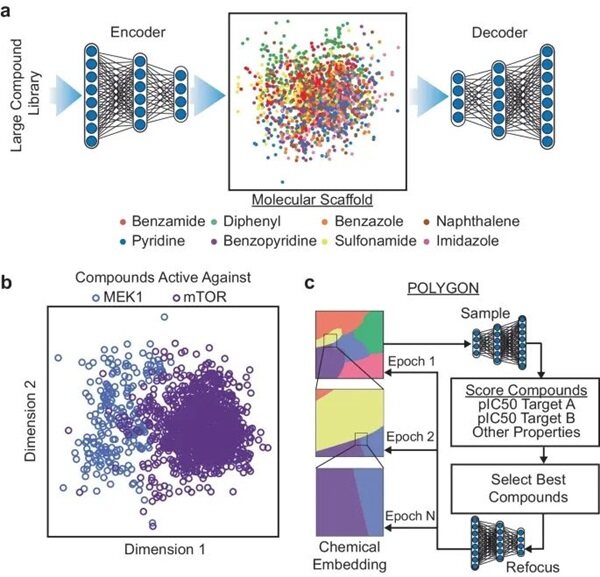
图示:嵌入化学空间以生成多药理药物的发现。
POLYGON的核心要点在于:
高准确率识别:在超过100,000种化合物的测试中,POLYGON能够准确识别多药理学相互作用,准确率达到82.5%,显示了其在预测方面的强大能力。
从头分子设计:该系统能够从头生成针对具有相互依赖关系蛋白质的分子化合物,通过深度学习模型自动生成满足特定化学属性的分子结构。
强化学习驱动:通过迭代采样和评分系统,POLYGON基于分子对特定靶标的预测抑制能力、合成可行性和药物类属性进行优化,实现对化学空间的有效探索和利用。
综合致死蛋白抑制:具体实例中,它成功合成了针对MEK1和mTOR的化合物,这两种蛋白质的联合抑制能有效杀死癌细胞,体现了其在精准医疗中的潜力。
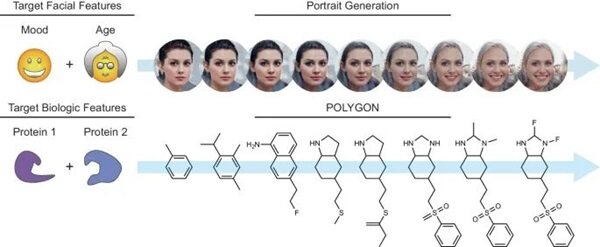
图示:肖像与小分子的生成模型
减少药物发现周期:虽然候选药物还需经过进一步化学优化,POLYGON显著缩短了药物发现的初始阶段,保留人类专业知识的同时加速了药物研发流程。
该研究以「De novo generation of multi-target compounds using deep generative chemistry」为题,于 2024 年 5 月 6 日发布在《Nature Communications》
论文链接:https://www.nature.com/articles/s41467-024-47120-y

点击链接https://bvjoh3z2qoz.feishu.cn/docx/O1Cndurj0oFVUhx1bS9cjySinLf,进入HPC&AI应用知识库
相关新闻
-
2026-05-19
共筑天津创新高地,国家超算互联网算力推介会成功举办
-
2026-05-16
河南省张敏调研国家超算互联网核心节点
-
2026-05-12
5·12全国防灾减灾日丨国家超算互联网全力支撑地震科学智能体部署上线
-
2026-05-07
论文解读 |上智院开源燧人分子基础大模型Suiren-1.0模型,同步上线超算互联网
-
2026-04-29
DeepSeek-V4 全矩阵上线!国家超算互联网筑牢“人工智能+”算力底座


