
新闻动态
刚刚,GLM-4.6 模型上线超算互联网 AI 社区,企业和开发者可快速下载模型文件进行部署开发。
9 月 30 日,智谱发布并开源 GLM 系列最新版本——GLM-4.6,作为其最强的代码 Coding 模型(较 GLM-4.5 提升 27%)。模型遵循 MIT 协议。
GLM-4.6 模型上线超算互联网 AI 社区
模型链接:
https://www.scnet.cn/ui/aihub/models/sugon_scnet/GLM-4.6
https://www.scnet.cn/ui/aihub/models/sugon_scnet/GLM-4.6-FP8
GLM-4.6 在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等多个方面实现全面提升。
高级编码能力:在公开基准与真实编程任务中,GLM-4.6 的代码能力对齐 Claude Sonnet 4,是国内已知的最好的 Coding 模型。
上下文长度:上下文窗口由 128K→200K,适应更长的代码和智能体任务。
推理能力:推理能力提升,并支持在推理过程中调用工具。
搜索能力:增强模型的工具调用和搜索智能体,在智能体框架中表现更好。
写作能力:在文风、可读性与角色扮演场景中更符合人类偏好。
综合评测
在 8 大权威基准:AIME 25、LCB v6、HLE、SWE-Bench Verified、BrowseComp、Terminal-Bench、τ^2-Bench、GPQA 模型通用能力的评估中,GLM-4.6 在部分榜单表现对齐 Claude Sonnet 4/Claude Sonnet 4.5,稳居国产模型首位。
真实编程评测
为了测试模型在实际编程任务中的能力,智谱团队在 Claude Code 环境下进行了 74 个真实场景编程任务测试。结果显示,GLM-4.6 实测超过 Claude Sonnet 4,超越其他国产模型。
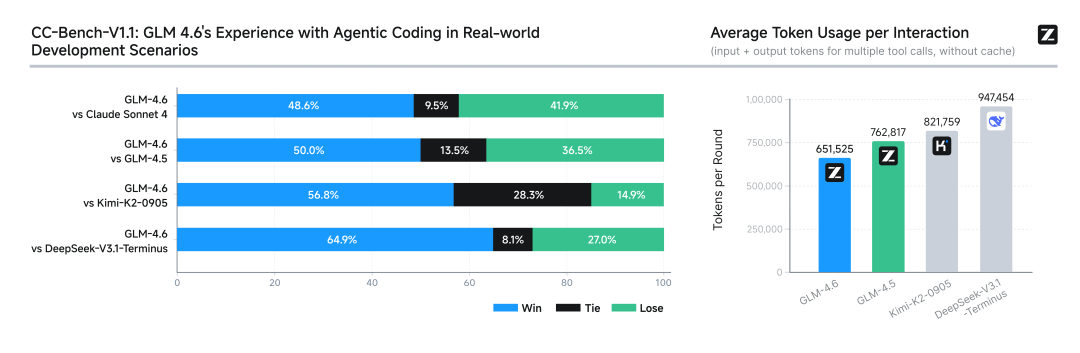
在平均 token 消耗上,GLM-4.6 比 GLM-4.5 节省 30% 以上,为同类模型最低。
为确保透明性与可信度,智谱已公开全部测试题目与 Agent 轨迹,供业界验证与复现。
截至目前,超算互联网 AI 社区已上线 10 余款智谱开源模型,包括新一代 GLM 模型系列、视频生成模型 CogVideoX 系列、端到端语音模型 GLM-4-Voice,以及多语言代码生成模型 CodeGeeX4 等,平台提供模型文件下载与在线推理服务。
智谱开源模型链接合集:
https://www.scnet.cn/ui/aihub/models?keyword=GLM&order=updateTime
相关新闻
-
2025-09-30
DeepSeek-V3.2-Exp 上线,训练推理提效
-
2025-09-26
超算互联网筑基“气象大脑”,数据共享叩开商业气象新生态
-
2025-09-26
超算&AI应用周报Vol.75 | 创作专属手办!腾讯3D生成模型上线,免费试玩
-
2025-09-24
Qwen系列上线,多图编辑模型Qwen-Image-Edit新版、全模态大模型Qwen3-Omni、视觉语言模型Qwen3-VL
-
2025-09-24
国家超算互联网与安徽省算力统筹调度平台互联互通



