


新闻动态
Meta 刚发布的 AI 模型系列 ——Llama 4,现已上线国家超算互联网。用户可在超算互联网 AI 社区下载 Llama 4 模型文件进行快速开发。Llama 4 支持阿拉伯语、英语、法语、德语等 12 种语言,方便全球用户进行开发和部署。
Llama 4 Scout 模型下载链接:
https://www.scnet.cn/ui/aihub/models?order=popularity&keyword=Llama-4-Scout-17B
为满足国内开发者需求,除 Llama 4 外,超算互联网已上线 Llama 系列原生、微调、量化、优化版本的多款模型,包括 Llama 2、Llama 3、Llama 3.1、Llama 3.2 等。超算互联网还推出了 GPU/异构加速卡基础镜像实操教程,3 分钟即可轻松部署和微调 Llama。
Llama 系列模型地址:https://www.scnet.cn/ui/mall/search/goods?keyword=Meta+LLama
千万 Token 上下文,性能 SOTA
Llama 4 是 Meta 基于混合专家(MoE)架构的模型系列,包括 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth(尚未推出)。
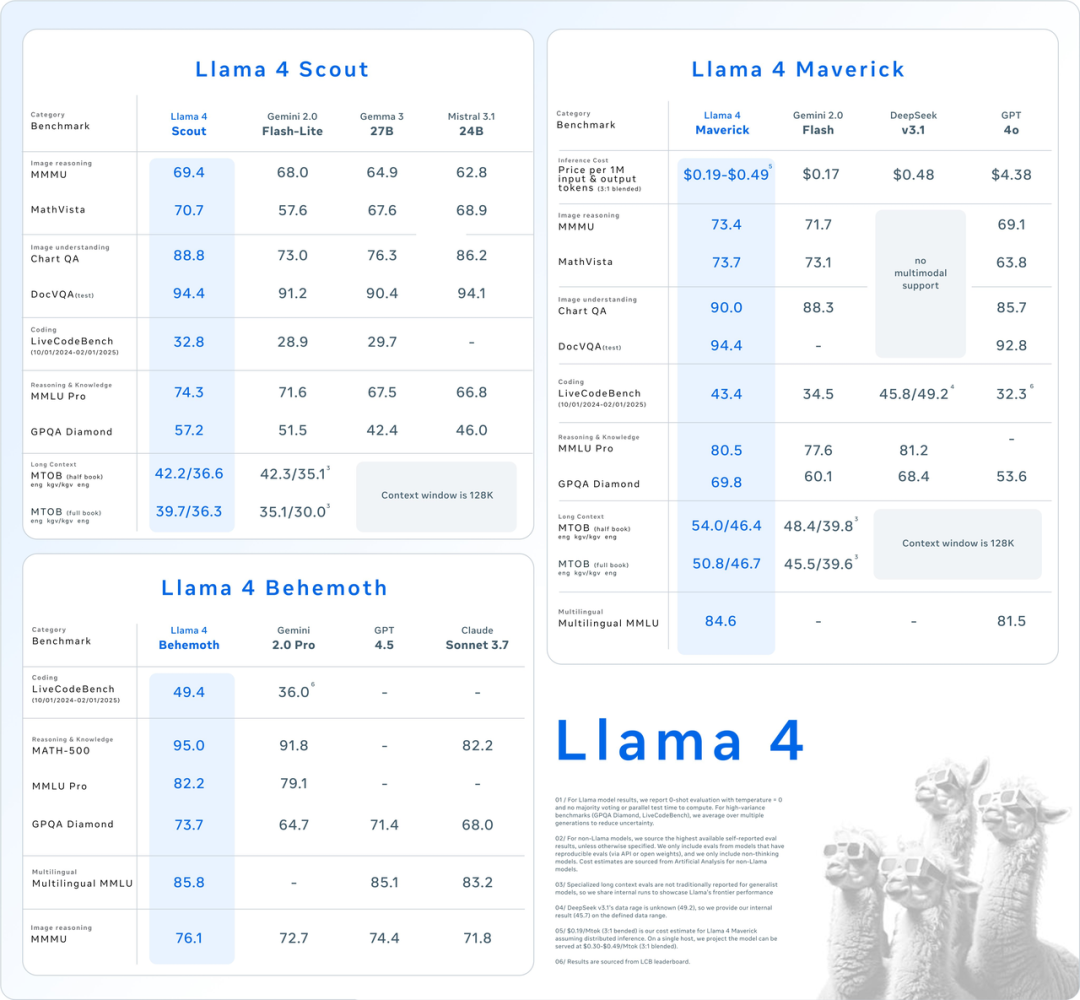
Llama 4 Scout:拥有 16 位专家、170 亿激活参数的多模态模型,比前几代 Llama 模型更强大,并拥有 10M 上下文窗口,在基准测试中,表现优于 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
Llama 4 Maverick:拥有 128 位专家、 170 亿激活参数,击败 GPT-4o 和 Gemini 2.0 Flash,同时在推理和编程方面取得了与 DeepSeek-V3 相当的结果 —— 激活参数不到一半。
Llama 4 Behemoth:16 位专家,288B 激活参数的超大超强模型,以上二者都由该模型蒸馏而来;在多个基准测试中,超过 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。不过,Llama 4 Behemoth 仍在训练中,将在未来几个月面世。
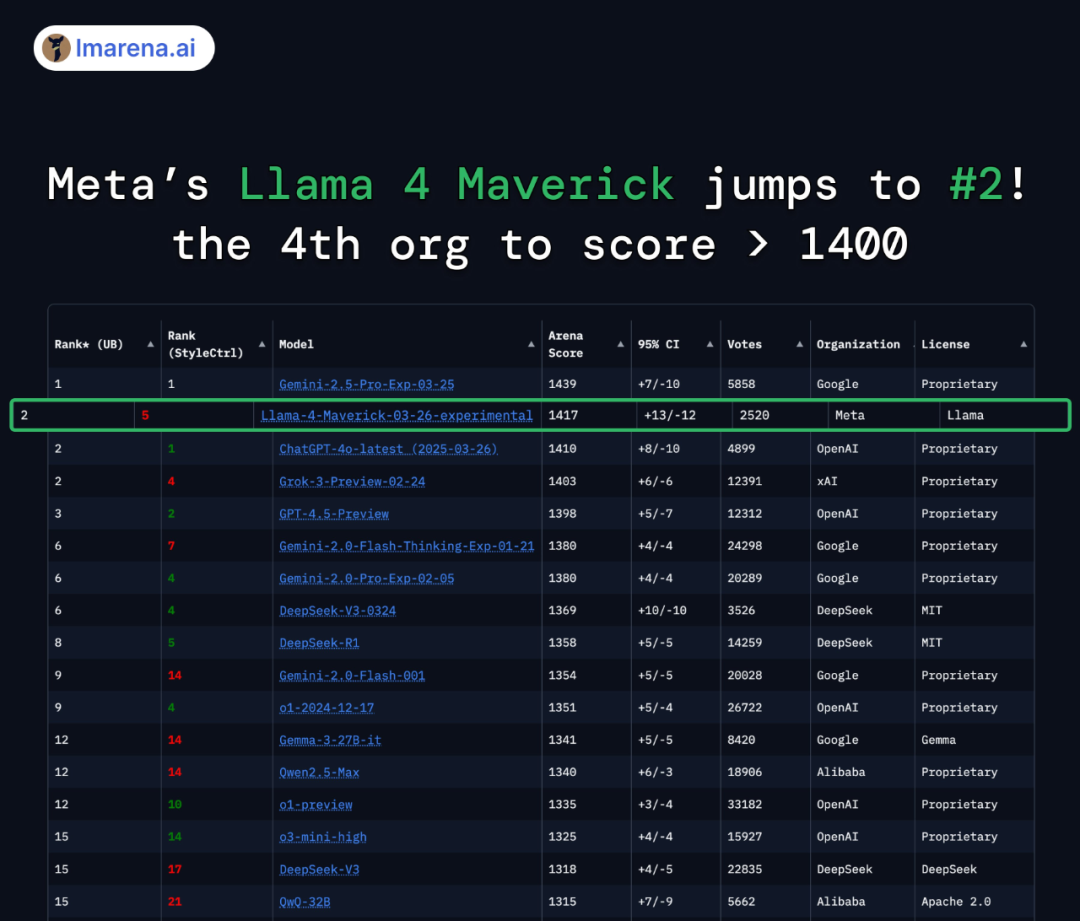
在大模型竞技场(Arena),Llama 4 Maverick 的总排名第二,成为第四个突破 1400 分的大模型。在困难提示词、编程、数学、创意写作等任务中排名均为第一;大幅超越了 Llama 3 405B,得分从 1268 提升到了 1417;风格控制排名第五。
Llama 4 Scout 的亮点在于支持 1000 万上下文,相当于可以处理 20 多小时的视频,单个 H100 GPU 可运行。
MoE 架构,原生多模态设计
Llama 4 采用的主要技术包括:
采用 MoE 架构:在 MoE 模型中,单个 token 仅激活总参数的一部分。与传统的稠密模型相比,MoE 架构在训练和推理时的计算效率更高,并且在相同的训练 FLOPs 预算下,能够生成更高质量的结果。
原生多模态设计:Llama 4 系列模型采用原生多模态设计,通过早期融合将文本和视觉 token 无缝整合到统一的模型骨干中。
模型超参数优化:Meta 还开发了一种新的训练技术,称为 MetaP,其能够可靠地设置模型超参数,例如每层的学习率和初始化规模。
后训练:后训练阶段,Meta 设计了一种精心策划的课程策略,与单一模态专家模型相比,该策略不会牺牲性能。在 Llama 4 中,通过采用不同的方法对后训练流程进行了全面改进:轻量级监督微调(SFT)> 在线强化学习(RL)> 轻量级直接偏好优化(DPO)。
目前,超算互联网已上线包含 Qwen2.5-Omni、DeepSeek、QwQ、Llama、Stable Diffusion、Gemma 等超 240 款国内外 AI 模型服务。此外,平台近期已上线 MCP 服务,用户可快速获取 SCNet 热门源码、模型服务、软件应用等信息。
相关新闻
-
2025-07-16
MiniMax-M1加入超算互联网Chatbot大家庭
-
2025-07-16
超算互联网亮相《新闻联播》,以数字经济赋能高质量发展
-
2025-07-16
超算&AI应用周报Vol.60 | 面壁智能「小钢炮」MiniCPM 4.0、阿里空间音频生成模型OmniAudio上线
-
2025-07-16
让AI重构毕业季的仪式感!超算互联网AI毕业季征集活动来啦
-
2025-07-16
最佳实践Vol.43 | 复现顶刊:LAMMPS模拟非晶合金非局部变形

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照