
新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算快讯、前沿应用、学术研究等。
本期超算&AI应用周报共4790字,预计阅读时间19分钟,您可以重点专注以下内容。
另外,文末有惊喜,我们为您准备了超算&AI应用知识库,可免费获得更多热门软件资源。
超算快讯:OpenFOAM-com v2306版本、OpenMM v8.1.1版本上线超算互联网,提高模拟精度和可靠性
前沿应用:Google Cloud Next 2024:首款自研Arm CPU,最强大模型公测,AI视频对垒Sora;苹果发布多模态模型 Ferret-UI;英特尔发布5nmAI芯片Gaudi3;Stability AI推出Stable LM 2 12B模型;斯坦福团队手机可跑的大模型火了
学术研究:浙大开发面向多组及纵向实验设计的各类组学数据的功能富集新方法;南科大开发研究细菌DNA甲基化组及其转录调控工具Bacmethy;首个解码mRNA序列大模型UTR-LM;「机器人+AI」发现电池最佳电解质
一、超算快讯:
OpenFOAM-com v2306版本上线超算互联网,提高模拟精度和可靠性
OpenFOAM是一款免费开源计算流体动力学(CFD)软件,可以解决从涉及化学反应、湍流和热传递的复杂流体流动,到声学、固体力学和电磁学的问题。
OpenFOAM v2306版本的改进和更新包括预处理、数值方法、求解器和物理模型、边界条件、后处理以及并行处理等,例如,改进了snappyHexMesh、checkMesh、新的并行预条件器、新的FPCG线性求解器、改进的vanDriest LES delta模型、新的Lagrangian粒子力:Coulomb,以及新的fvOption:fanMomentumSource等。
OpenFOAM-com v2306版本现已上线超算互联网,包括以下亮点:
提高模拟精度和可靠性:通过改进数值方法、求解器和物理模型,OpenFOAM v2306能够提供更精确的模拟结果。
增强多物理场耦合能力:模块化的求解器改进有助于更好地集成和耦合不同物理场,如流体动力学、热传递、化学反应等。这使得OpenFOAM v2306能够处理更复杂的工程问题,推动多学科领域的研究。
提升计算效率:性能优化和并行处理改进意味着更快的计算速度和更好的资源利用效率。这对于需要大量计算资源的大规模模拟来说尤为重要,可以显著减少研究时间和成本。
下载链接:
https://www.scnet.cn/ui/mall/detail/goods?type=software&common1=APP_SOFTWARE&id=1775358757083389954&resource=APP_SOFTWARE
OpenMM v8.1.1版本上线超算互联网,可免费下载使用
OpenMM是一款开源的分子模拟软件包,专注于高效、高性能的计算化学与生物物理学模拟。它包含两部分:一部分是用于执行多种分子模拟计算(如力评估、数值积分、能量最小化等)的库,另一部分是提供高级接口的Python库,用于运行模拟。
OpenMM v8.1.1版本现已上线超算互联网,OpenMM功能特点主要包括:
硬件加速:OpenMM充分利用了现代GPU和多核CPU的强大并行计算能力,通过CUDA和OpenCL接口实现对大模型分子系统的快速动力学模拟,使得其在处理复杂的生物分子系统时能够显著提升计算速度;
广泛的力场支持:OpenMM支持多种经典的力场模型,包括AMBER、CHARMM、OPLS-AA等,可以方便地添加自定义力场以适应不同类型的分子模拟需求;
集成多种模拟方法:除了传统的分子动力学(MD)模拟外,还支持布朗运动(BD)、蒙特卡洛(MC)模拟以及自由能微扰(FEP)等多种模拟技术,可用于研究蛋白质折叠、配体结合、离子通道门控等生物学过程。
下载链接:
https://www.scnet.cn/ui/mall/detail/goods?type=software&common1=APP_SOFTWARE&id=1778321642372440066&resource=APP_SOFTWARE
二、前沿应用:
Google Cloud Next 2024:首款自研Arm CPU,最强大模型公测,AI视频对垒Sora
本周,Google Cloud Next 2024大会可是太精彩了,谷歌一连放出不少炸弹。
升级「视频版」Imagen 2.0,下场AI视频模型大混战
发布时被Sora光环掩盖的Gemini 1.5 Pro,免费开放了
首款Arm架构CPU发布,全面对垒微软、亚马逊、英伟达、英特尔
此外,谷歌的AI超算平台也进行了一系列重大升级——最强TPU v5p上线、升级软件存储,以及更灵活的消费模式,都让谷歌云在AI领域的竞争力进一步提升。
Gemini 1.5 Pro:
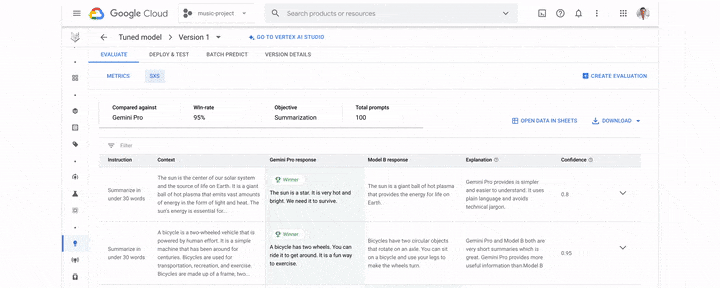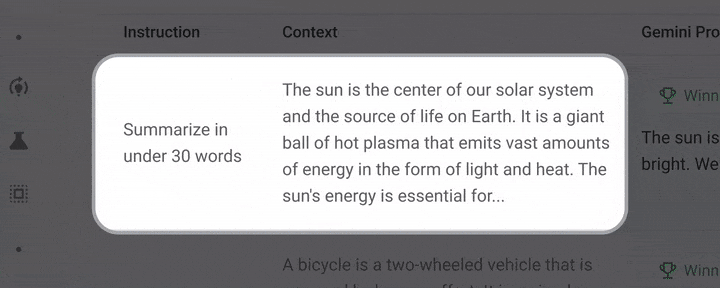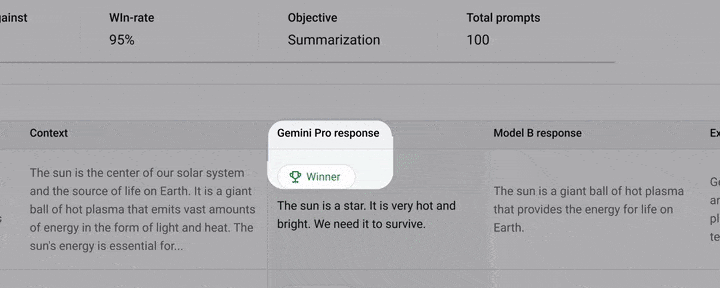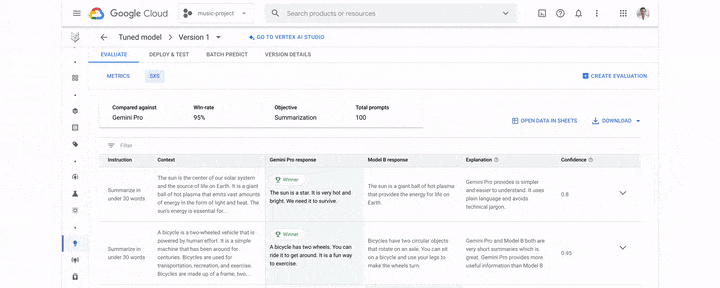
Gemini 1.5 Pro最大的亮点无疑是上下文窗口长度:从128k到最多100万,比Claude 3中最大的200K上下文,直接高出了五倍。不仅如此,Gemini 1.5 Pro API首次增加了音频理解功能,这直接就无缝打破了文本、图像、音频和视频的边界,一键开启多模态文件之间的无缝分析。
Imagen 2.0:

AI生图工具Imagen,现在可以生成视频了。只用文本提示,Imagen就能创作出实时的动态图像,帧率为每秒24帧,分辨率达到360x640像素,持续时间为4秒。并且,谷歌对Imagen 2.0也升级了图像编辑功能,增加了图像修复、扩展、数字水印功能。
自研Arm架构CPU处理器Axion:
据称这款CPU处理器Axion,将提供比英特尔CPU更好的性能和能源的效率,其中性能提高50%,能源效率提高60%。现在,Axion芯片已经在为YouTube 广告、Google Earth引擎提供加持,很快就可以在谷歌计算引擎、谷歌Kubernetes引擎、Dataproc、Dataflow、Cloud Batch等云服务中使用。不仅如此,原本在使用Arm的客户,无需重新架构或者重写应用程序就可以轻松地迁移到Axion上来。(新智元)
内容链接:
https://mp.weixin.qq.com/s/66TgyKWsHppPgz_ANonwGg
超越GPT-4V,苹果发布多模态模型 Ferret-UI
4月8日,苹果发表了一个能“看懂”手机屏幕上并能执行任务的多模态模型“Ferret-UI”,专为增强对移动端 UI 屏幕的理解而定制,配备了引用(referring)、定位(grounding)和推理(reasoning)功能。
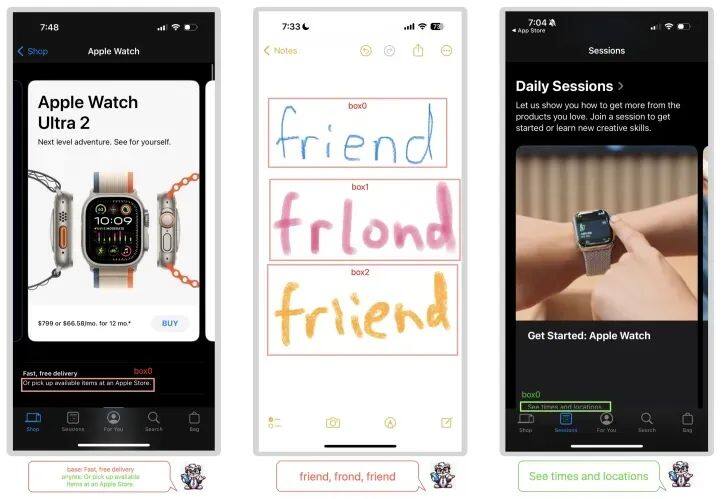
Ferret-UI关键要点如下:
在部分UI 任务上表现超越GPT-4V:Ferret-UI在众多基础及高级UI任务上展现出优于GPT-4V的表现,尤其是在与iPhone相关的任务中。在OCR、图标识别、控件分类等任务上,Ferret-UI的准确率远高于GPT-4V。
跨操作系统知识迁移能力:在安卓平台的高级任务上,尽管未针对安卓数据训练,Ferret-UI仍能在高级任务中取得良好成绩,显示出跨操作系统知识迁移能力。
引入“任何分辨率”技术:Ferret-UI 的一个关键创新是在 Ferret 的基础上引入了“任何分辨率”技术,解决了移动设备屏幕长宽比多样化的难题。
分层次任务设计提升模型能力:研究团队设计了从基础识别分类任务到高级对话推断任务的分层次学习路径,使Ferret-UI逐步提升对UI元素、功能和上下文的理解。
论文链接:https://arxiv.org/pdf/2404.05719.pdf
英特尔发布5nmAI芯片Gaudi3,训练比H100快40%,推理快50%

4月9日晚,英特尔发布性能新一代Gaudi3 AI 加速芯片,采用台积电5nm工艺,支持128GB HBMe2内存。最直接的升级体现在性能和成本方面:
在AI模型算力中,相比于英伟达H100 GPU,Gaudi3 AI芯片的模型训练速度、推理速度分别提升40%和50%,平均性能提高 50%,能效平均提高40%,而成本仅为H100的一小部分。
相比最新英伟达H200,Gaudi3 AI芯片的推理速度竟然也提升30%。堪称最强 AI 芯片。(钛媒体AGI)
内容链接:
https://mp.weixin.qq.com/s/gonb_Q8CCGeDumKHkw22tA
Stable LM 2 12B以小搏大,颠覆多语种模型格局
4月9日,Stability AI推出Stable LM 2 12B模型,作为其新模型系列的进一步升级,该模型基于七种语言的2万亿Token进行训练,拥有更多参数和更强性能。
在Open LLM Leaderboard和MT-Bench基准测试中,其性能超越了诸如Llama 2 70B等开源竞品,尤其是在零样本和少样本任务上表现出色。
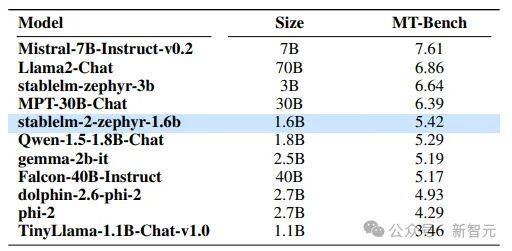
Stable LM 2 12B关键要点如下:
参数规模与性能:Stable LM 2 12B拥有120亿参数,性能显著超越Llama 2 70B等开源模型,特别是在零样本和少样本任务中表现出SOTA水平;
硬件适应性与任务处理能力:能在各种常见硬件上顺畅运行,且能处理通常需要更大模型(如MoE)才能完成的复杂任务;
指令微调增强:指令微调版本增强了工具使用和函数调用能力,适用于多种场景;
架构改进:与LLaMA相比,Stable LM 2 12B采用旋转位置嵌入提升吞吐量,使用带有学习偏置项的LayerNorm代替RMSNorm,移除无关偏置项以优化性能;
预训练方法与数据处理:采用自回归序列建模、FlashAttention-2优化、BFloat16混合精度进行预训练,使用Arcade100k分词器处理多语言数据;
模型微调策略:在Hugging Face Hub公开指令数据集上进行有监督微调(SFT),使用 UltraChat、WizardLM等多个数据集,共826,938个样本,并实施直接偏好优化。(DPO)
内容链接:https://stability.ai/news/introducing-stable-lm-2-12b
超越GPT-4,斯坦福团队手机可跑的大模型火了,一夜下载量超2k
近日,斯坦福大学研究人员推出的 Octopus v2火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。
Octopus-V2-2B 是一个拥有 20 亿参数的开源语言模型,专为 Android API 量身定制,旨在在 Android 设备上无缝运行,并将实用性扩展到从 Android 系统管理到多个设备的编排等各种应用程序。
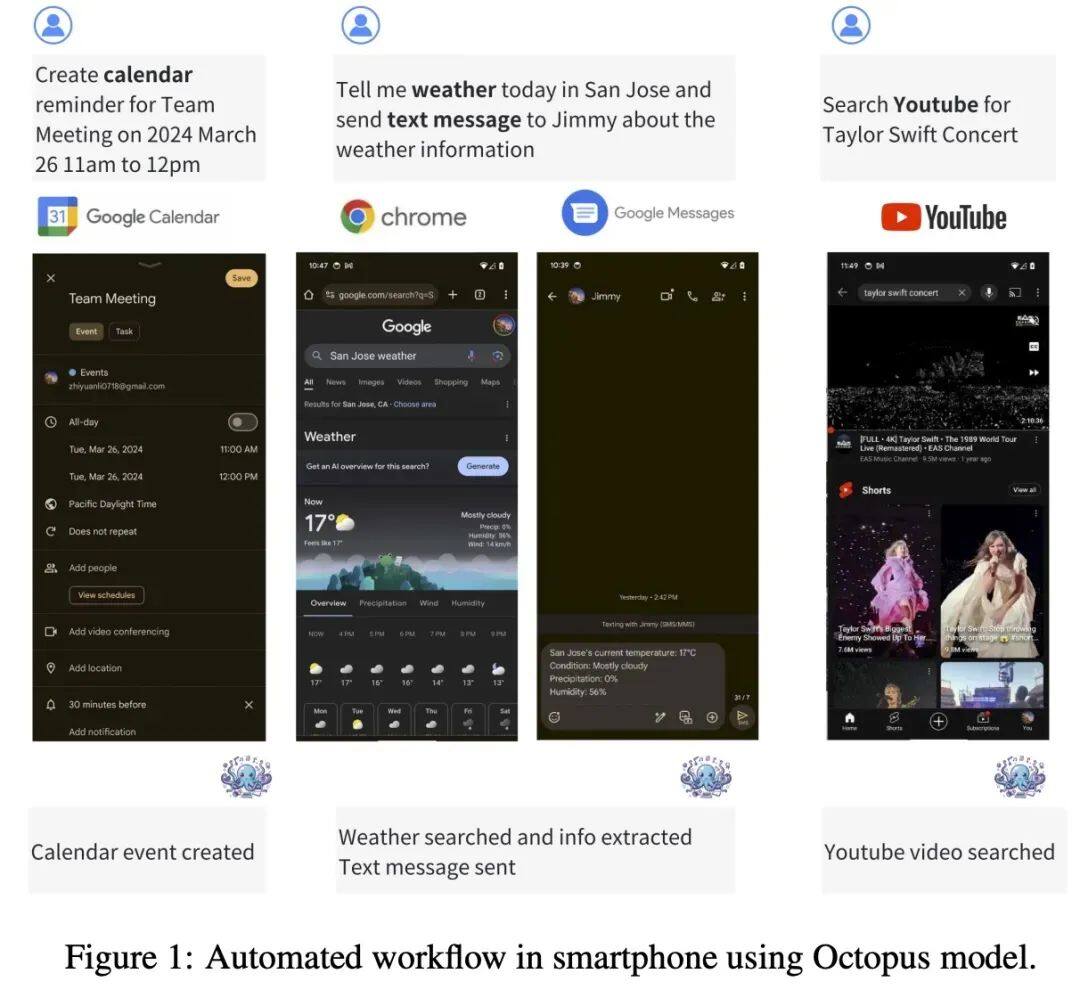
20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。(机器之心)
论文地址:https://arxiv.org/abs/2404.01744
三、学术研究:
浙大蒋超组开发面向多组及纵向实验设计的各类组学数据的功能富集新方法
近期,浙江大学生命科学研究院蒋超实验室在Briefings In Bioinformatics 上在线发表了题为“Generalized reporter score-based enrichment analysis for omics data”的研究论文。该团队开发了面向多组学及纵向组学数据富集分析的Generalized Reporter Score-based Analysis(GRSA)方法及对应R软件包,这是一种灵活的,可用于复杂多组学数据的功能富集新方法。
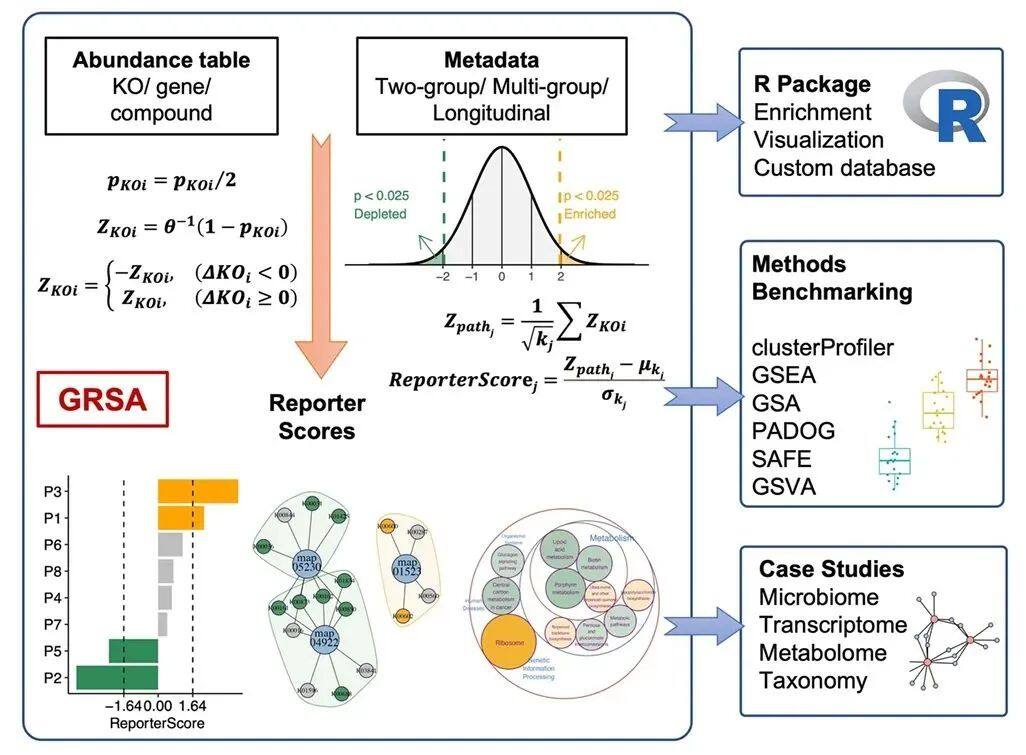
研究亮点:
广义报告评分富集分析(GRSA)和R软件包ReporterScore,将经典RSA的功能扩展到多组和纵向实验设计,并与各种类型组学数据兼容。
与常用的富集分析方法相比,GRSA具有更高的灵敏度。
GRSA可以应用于各种分层和关系数据库,并执行自定义的富集分析,如物种分类富集分析。
论文链接:
https://academic.oup.com/bib/article/25/3/bbae116/7636146
南科大开发研究细菌DNA甲基化组及其转录调控工具Bacmethy
近日,南方科技大学医学院杨亮、南方科技大学医院医学研究中心刘洋团队在iMeta在线联合发表研究文章,开发了一种利用SMRT-seq数据的生物信息学工具Bacmethy,提供多种分析模块。Bacmethy的代码是开源的,同时提供Docker镜像。
研究亮点:
Bacmethy工具提供了一个一站式的分析和可视化流程,可以表征细菌DNA甲基化修饰的特性并预测其调控模式;
Bacmethy配备了本地运行以及在线分析服务,方便缺乏编程技能的研究人员;
研究人员通过Bacmethy可揭示DNA甲基化如何调节细菌的细胞及生理功能的分子机制。
论文链接:https://doi.org/10.1002/imt2.186
首个解码mRNA序列大模型UTR-LM,提升蛋白质表达预测准确性
近日,来自普林斯顿大学和斯坦福大学与RVAC Medicines和Zipcode Bio等团队联合开发了首个解码mRNA序列大模型:5′ UTR语言模型(UTR-LM),该模型采用先进的人工智能架构,通过自学大量mRNA序列,能深入理解并预测这一区域如何调控基因的翻译过程,进而影响蛋白质生成效率。
研究团队还巧妙利用了额外的生物物理信息(如二级结构、能量状态)来增强模型准确性,使其能更精确地服务于基因功能研究与潜在的药物开发应用。
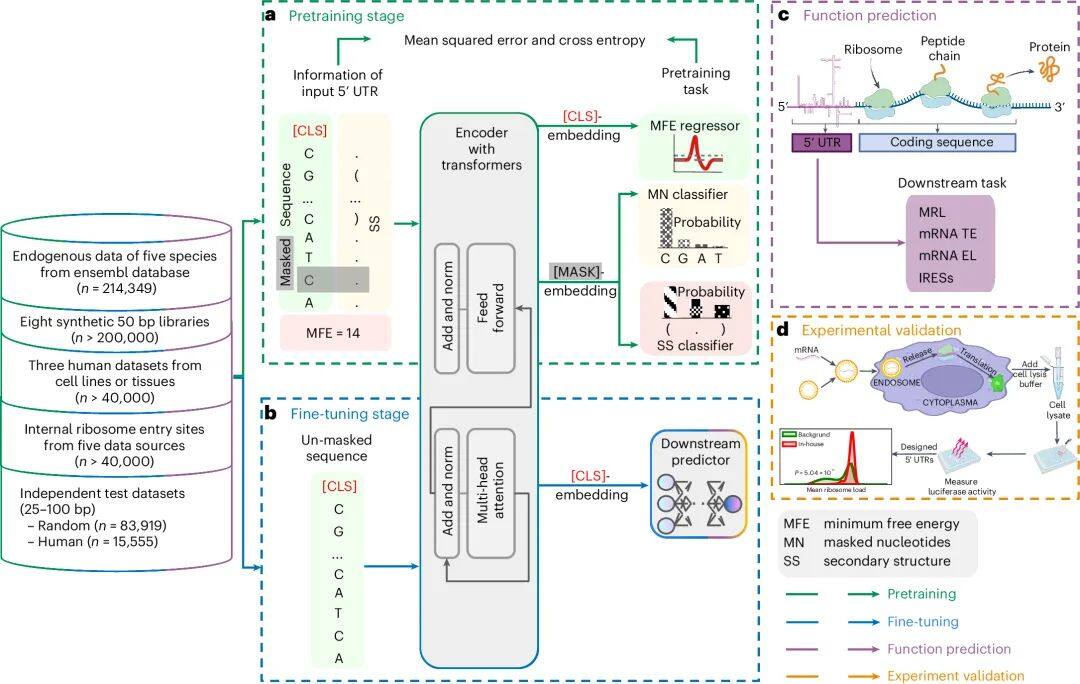
mRNA非翻译区域语言模型
UTR-LM模型在分析mRNA起始段表现突出,能精准预测多个关键指标,如核糖体附着程度、翻译效率、基因表达强度及核糖体进入位置,且优于现有模型。
实际实验中,根据UTR-LM预测结果设计的新5′ UTR序列成功提升了蛋白质产量,显示其在生物技术和医疗应用中的巨大潜力。
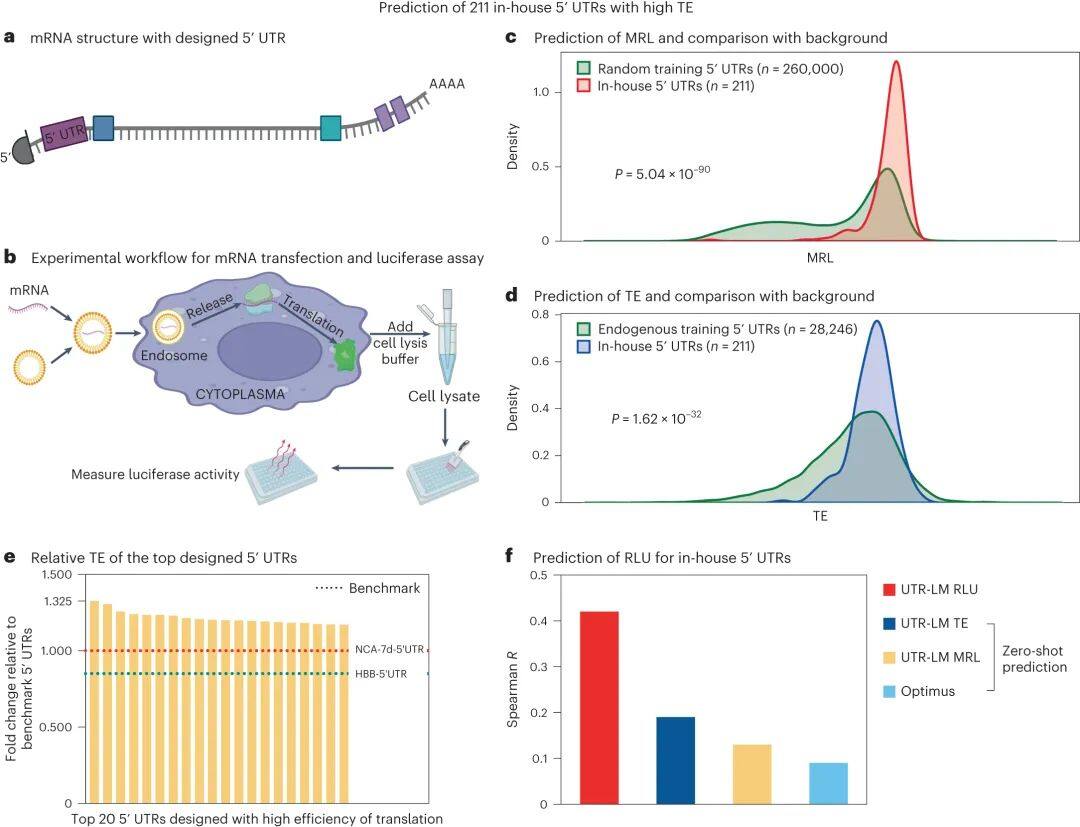
湿实验设计并验证了包含211个具有高TE的5' UTR库
UTR-LM模型不仅强大,而且易于理解。它能清晰解释不同物种间mRNA起始段的差异,精准锁定调控基因翻译的关键区域,并识别像Kozak序列(KCS)这样的重要调控基序及其典型模式(如CCACC)。这些特性有助于深化对mRNA 5′ UTR功能调控机制的理解。(DrugAI)
论文链接:
https://www.nature.com/articles/s42256-024-00823-9
「机器人+AI」发现电池最佳电解质,加速材料研究
近期,美国西北太平洋国家实验室和阿贡国家实验室的研究团队创建了一个高通量实验(HTE)机器人平台,结合高通量实验和主动学习算法(特别是贝叶斯优化,BO),以快速筛选出对阳极电解质具有最佳溶解度的二元有机溶剂。这一突破显著加速了清洁能源技术新材料的研发,特别适用于高性能氧化还原液流电池(RFB)电解质设计。
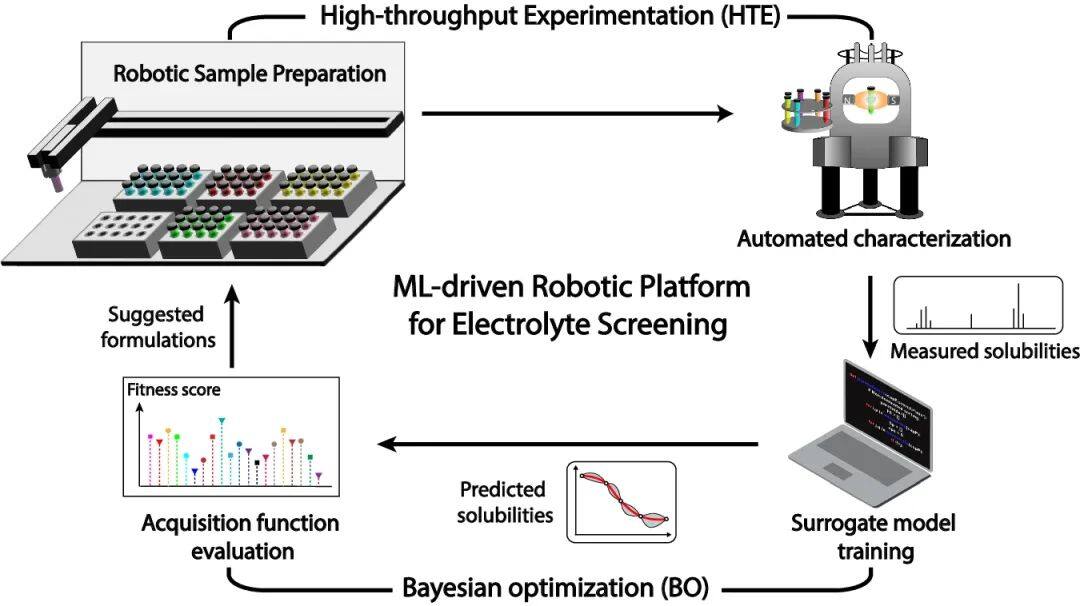
基于机器学习(ML)引导的高通量实验平台的闭环电解质筛选过程示意图
研究致力于优化氧化还原活性分子在非aqueous液流电池(NRFB)中的溶解度,以提升电池的能量密度。为确保数据精确、实验高效,研究者借助自动化高通量筛选平台创建了一个专门的溶解度数据库,面对众多可能的溶剂混合物,研究采用了“贝叶斯优化”(BO)策略,结合闭环实验流程,有效减少了不必要的尝试,加速了最优溶剂组合的找寻过程。
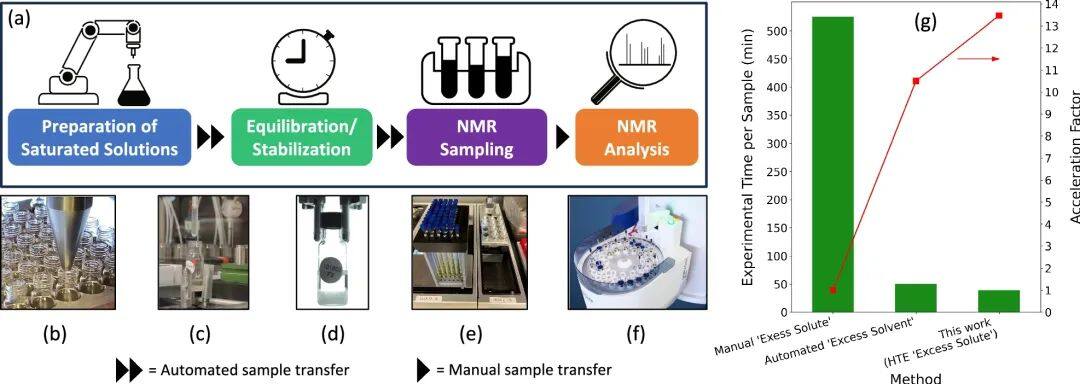
自动化高通量实验 (HTE) 平台概述
研究人员挑选了22种溶剂,配对形成2079种二元组合,旨在找出能大幅提升BTZ溶解度(至少达6.20 M)的最优溶剂配方。在测试的数千种组合中,含1,4-二恶烷的混合物表现尤为出色。该方法高效,仅需考察约十分之一的候选溶剂便找到了理想解决方案。
该研究以《An integrated high-throughput robotic platform and active learning approach for accelerated discovery of optimal electrolyte formulations》为题,发布在《Nature Communications》。
论文链接:
https://www.nature.com/articles/s41467-024-47070-5

相关新闻
-
2026-04-15
天津算力券政策:企业免费算力红利这样领
-
2026-06-10
618福利提前享!超算互联网智能文档解析上线,长文档、公式、表格轻松处理
-
2026-06-09
超智融合算力就绪,中国AI气象迎来“最强大脑”
-
2026-05-31
《新闻联播》重磅聚焦——国家超算互联网核心节点铸就科技强国算力基石
-
2026-05-28
加速科学计算智能体普及 国家超算互联网点亮2026天津智博会


